
Background
This article is about how I acquaint myself with object detection methods and their models. Let’s begin by explaining why I am interested in object detection. Object detection problem is interesting because if we can detect objects of interest accurately, we can then count items, classify them, work out their spatial interaction or relationship and do much more. Unlike a classification task which aims to identify the most prominent or relevant object in an image, we are interested in knowing which, how many and where all objects are in an image or a video. Object detection is a much broader problem. Unlike a segmentation task which aims to assign each pixel in an image predefined classes, we are only interested in the whereabout or the vicinity of an object without concerning details at pixel level. Some computer vision tasks may not need to go down to the pixel level, including head counting, identifying the presence or absence of an objects, and so on.
The need to detect an object or many objects in a scene is nothing new. However, the most exciting fact is that we can improve object detection performance by adapting convolutional neural network architecture which has proven to be suitable in image classification, natural language processing, computer vision, audio processing and more.
Approaches
My reading suggests that there are two main schools of thoughts. The first approach is a two-stage system, involving two separate models. The first model scans an image and then provides a basket of region candidates that likely contain an object of interests (region proposal stage). The second model can then do less work by taking in only these proposals and try to classify them. The famous member from this school is the R-CNN family.
However, one of the main drawbacks of the two-stage system is its inefficiency in deployment as well as training. Two separate models are trained in series and both are needed during deployment, thereby making end-to-end training impossible. The second approach, by and large, tries to address this inefficiency. It advocates a single model that scans an image, estimates a pool of possible object locations and then classifies them. In this way, this model can be trained end-to-end, optimizing the complementary tasks simultaneously. For a long time, the two-stage approach yields better performance than a single-model approach. Until fairly recently, scientists have worked out a number of tricks that enables a single model to supersede two-stage models. Famous members include YOLO family, SSD, RetinaNet, etc.
 {width=10%}
{width=10%}
Furthermore, within this one-stage approach, we have seen two variants, namely anchor-based and anchor-free. The anchor-based approach relies on anchor boxes that are pre-determined and covered the entire image. Because they can be controlled via their aspect ratios and scales, these boxes capture object of various sizes and shapes. In much of the same way as region proposals, these anchor boxes serve the same purpose, but since they are set inside the model architecture, the model must go through and evaluate them all to detect any object of various shapes and sizes. This can be very useful if we have a rough idea on the kind of shapes and sizes of our objects of interest.
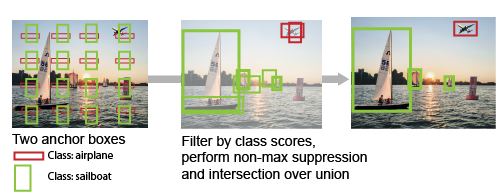
The anchor-free approach is closer conceptually to segmentation than anchor-based approach. Instead of relying on pre-defined anchor boxes as region candidates, anchor-free seeks to identify pixels that are useful for defining an object boundary. Since it operates on pixel level, it bears resemblance to segmentation tasks. For instance, to obtain object boundaries, cornerNet uses the corners while FCOS uses the center-of-mass.

Modern object detection methods involve the following elements:
- Anchor boxes
- Feature pyramid network
- Focal loss
- Non-max suppression
How these elements play out in the network architecture and during training will be delineated when we go through my python source code in the latter parts of this object detection series.