
Model training and testing
Generally speaking, there is nothing special in how I have trained and tested the models. Because the toy problem is so simple that there is hardly any need to do much fine-tuning or hyper-parameter search. However, I have used two separate models, namely RetinaNet to detect shapes and a small classifier model to identify colors of the shapes.
The RetinaNet and color classifier are trained in series. First, RetinaNet proposes detected boxes which are verified to see if the confidence scores of the boxes exceed a threshold and to see if the boxes overlap with the ground truth sufficiently. I chose these two criteria to ensure the training of the color classifier could go smoothly.
Once the detected boxes met the criteria, the patches denoted by the boxes are cropped out from the entire image. I have used these patches to train the color classifier. The reason is twofold. A patch is smaller than the image, so training becomes faster and easier. The color is independent to the size of object. Cropping the object out and resizing them to a fixed dimension make the process more efficient.
CONFIDENCE = 1e-4 # have enough confidence on the detected bounding boxes to crop out patches to train a classifier
IMG_SIZE = (32,32) # cropped image size, classifier input dimension
MIN_CONFIDENCE = 0.1
IOUTHRESHOLD = 0.5 # overlap 50% or more
FREQ = 2 # check patch frequency
def locate_good_boxes(boxes_class):
'''
find good enough detected boxes and to crop patches out from images to train
a classifier
'''
top_boxes = []
'''
maybe able to add a rule that resamples the boxes to give a more balanced dataset
'''
for _, box_scores in boxes_class.items():
if len(box_scores) > 0:
# score, bbox = box_score
sorted_scores = [torch.unsqueeze(item[-1], dim=0) for item in box_scores if item[0] > MIN_CONFIDENCE]
top_boxes += sorted_scores
if len(top_boxes) == 0:
return None
else:
return torch.cat(top_boxes, dim=0)
def scores_min_bar_test(scores):
scores = scores.cpu().numpy()
idxs = np.where(scores > CONFIDENCE)[0]
if len(idxs) > 0:
return idxs
else:
return None
def find_enough_overlap(b, shape_gt, idxs, scores, classification, transformed_anchors, labels_meaning, per_label=False):
'''
find the overlap between ground truth boxes and detected boxes
assign the ground truth class label to the detected bounding boxes for classifier
per_label is a special case used during validation / testing
'''
boxes_class = pair_up_bbox_color_labels(idxs, classification, transformed_anchors, scores, labels_meaning)
if per_label:
top_boxes = locate_top_boxes(boxes_class)
a, a_key = put_anchor_boxes_per_label_array(top_boxes)
else:
a = locate_good_boxes(boxes_class)
if a is not None:
intersection, area, ratio = calc_iou(a,b, return_intersection=True)
if per_label:
# dictionary like this makes debugging far easier
b_shape_dict_col_indices = {labels_meaning[item]:i for i, item in enumerate(shape_gt.cpu().numpy().tolist()[0])}
good_overlapped_boxes = {}
for shape, (score, bbox) in top_boxes.items():
shape_col = b_shape_dict_col_indices[shape]
row_index = a_key[shape]
r = ratio[row_index, shape_col]
if r >= IOUTHRESHOLD:
good_overlapped_boxes[shape] = (score, bbox)
else:
print ('insufficent overlap for shape %s' %shape)
if len(good_overlapped_boxes) == 0:
return None
else:
return good_overlapped_boxes
else:
# pytorch likes named tuple, therefore it is so python friendly
max_intersection = torch.max(ratio, dim=1)
max_areas = max_intersection.values
max_indices = max_intersection.indices
mask = max_areas >= IOUTHRESHOLD
big_enough_predicted_boxes = a[mask]
big_enough_inputs = max_indices[mask]
'''
sometimes when all detected boxes fall onto a single object,
it may use the wrong label as it just assigns the same label for all
'''
return big_enough_predicted_boxes, big_enough_inputs
else:
return None
def prepare_patches(big_enough_predicted_boxes, big_eough_inputs, c, img_copied,
shape_color_dict = None):
# make sure datatype is correct
big_enough_predicted_boxes = big_enough_predicted_boxes.long()
big_enough_predicted_boxes = torch.clamp(big_enough_predicted_boxes, min=0)
y_start = big_enough_predicted_boxes[:,1]
y_end = big_enough_predicted_boxes[:,3]
x_start = big_enough_predicted_boxes[:,0]
x_end = big_enough_predicted_boxes[:,2]
L = len(big_enough_predicted_boxes)
if L > 0:
temp_img_list = []
label_list = []
for k in range(L):
# may not always follow the same sequence, can contain skips
if shape_color_dict:
shape = big_eough_inputs[k]
color, which = shape_color_dict[shape]
else:
which = big_eough_inputs[k]
temp_img = img_copied[which,
:,
y_start[k]:y_end[k],
x_start[k]:x_end[k]]
# try not to do interpolation on gpu, it can take up too much memory
temp_img = torch.unsqueeze(temp_img, dim=0).cpu()
patch = F.interpolate(temp_img, IMG_SIZE, mode='bilinear', align_corners=False)
temp_img_list.append(patch)
if shape_color_dict:
label_list.append(torch.from_numpy(np.array([inverse_color_labels[color]])))
else:
label_list.append(torch.unsqueeze(c[big_eough_inputs[k]], dim=0))
return temp_img_list, label_list
else:
print ('no patches')
return None
def cat_N_items(items, dim=0):
return [torch.cat(item, dim=dim) for item in items]
def copy_reorganize_inputs(annot, color_label_gt, img_gpu):
b = annot[:,:,0:4].reshape(-1,4).cpu()
c = color_label_gt.reshape(-1)
shape_gt = annot[:,:,-1].cpu()
# repeat 123 = 111222333
img_copied = torch.repeat_interleave(img_gpu, annot.shape[1], dim=0)
return b, c, shape_gt, img_copied
def check_validity_predicted_bboxes(img_gpu, annot, color_label_gt, retinanet, iter_num):
print ('iter num %d: check_validity_predicted_bboxes' %iter_num)
retinanet.calculate_focalLoss = False
retinanet.eval()
patches = None # default value
with torch.no_grad():
img_gpu, annot, color_label_gt = cat_N_items([img_gpu, annot, color_label_gt])
b, c, shape_gt, img_copied = copy_reorganize_inputs(annot, color_label_gt, img_gpu)
scores, classification, transformed_anchors = retinanet(img_gpu.cuda())
scores = scores.cpu()
classification = classification.cpu()
transformed_anchors = transformed_anchors.cpu()
idxs = scores_min_bar_test(scores)
if idxs is not None:
found = find_enough_overlap(b, shape_gt, idxs, scores, classification,
transformed_anchors, labels_meaning, per_label=False)
if found is not None:
big_enough_predicted_boxes, big_enough_inputs = found
patches = prepare_patches(big_enough_predicted_boxes, big_enough_inputs, c, img_copied)
retinanet.train()
return patches
From my experience, the color classifier had a delay in beginning its training because it took a few epochs for the RetinaNet to produce good enough detected boxes that overlap with the objects
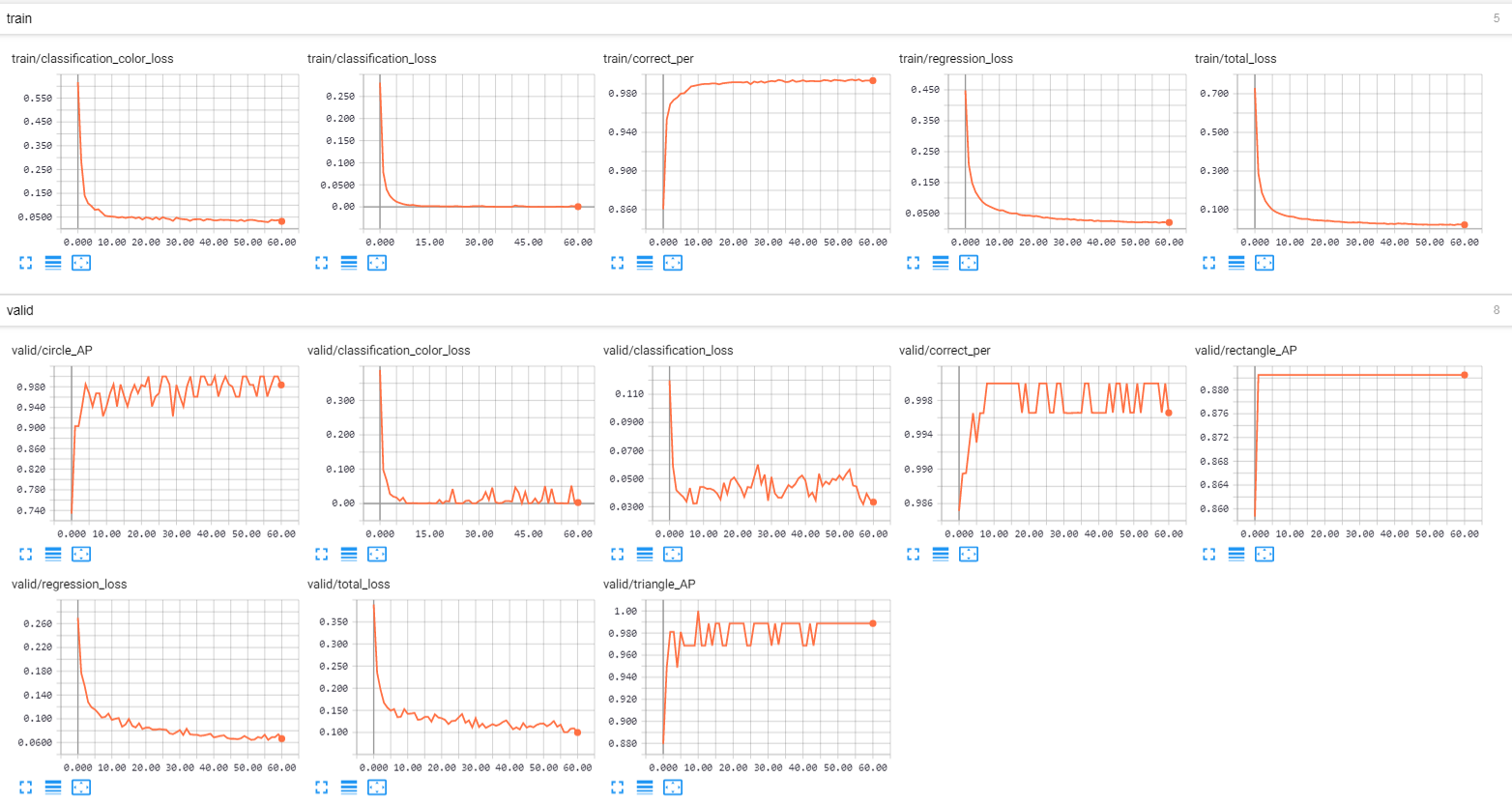
The classification_color_loss is cross entropy loss; classification loss is focal loss. Correct_per is the percentage of colors correctly identified. Regression loss is the square of the distances between the ground truth bounding boxes and the detected boxes. The task seems trivial to the network so the loss reduces exponentially and the average precision of the shape rises to 100% (within 50 epochs).
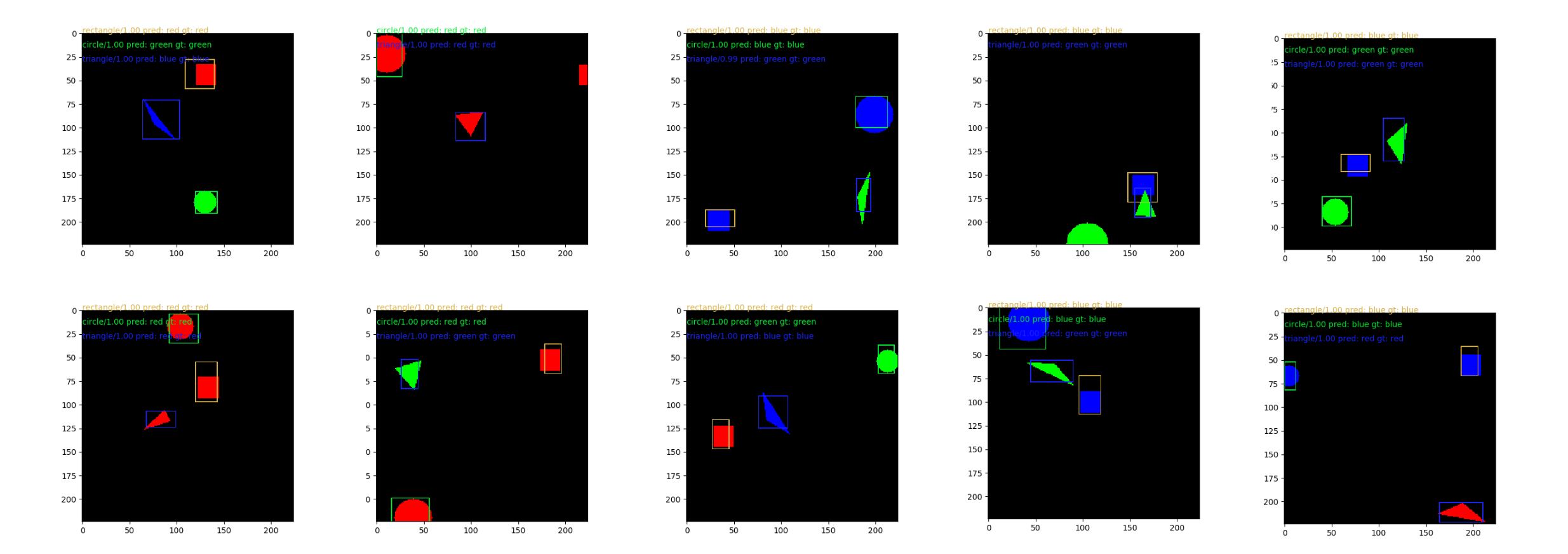
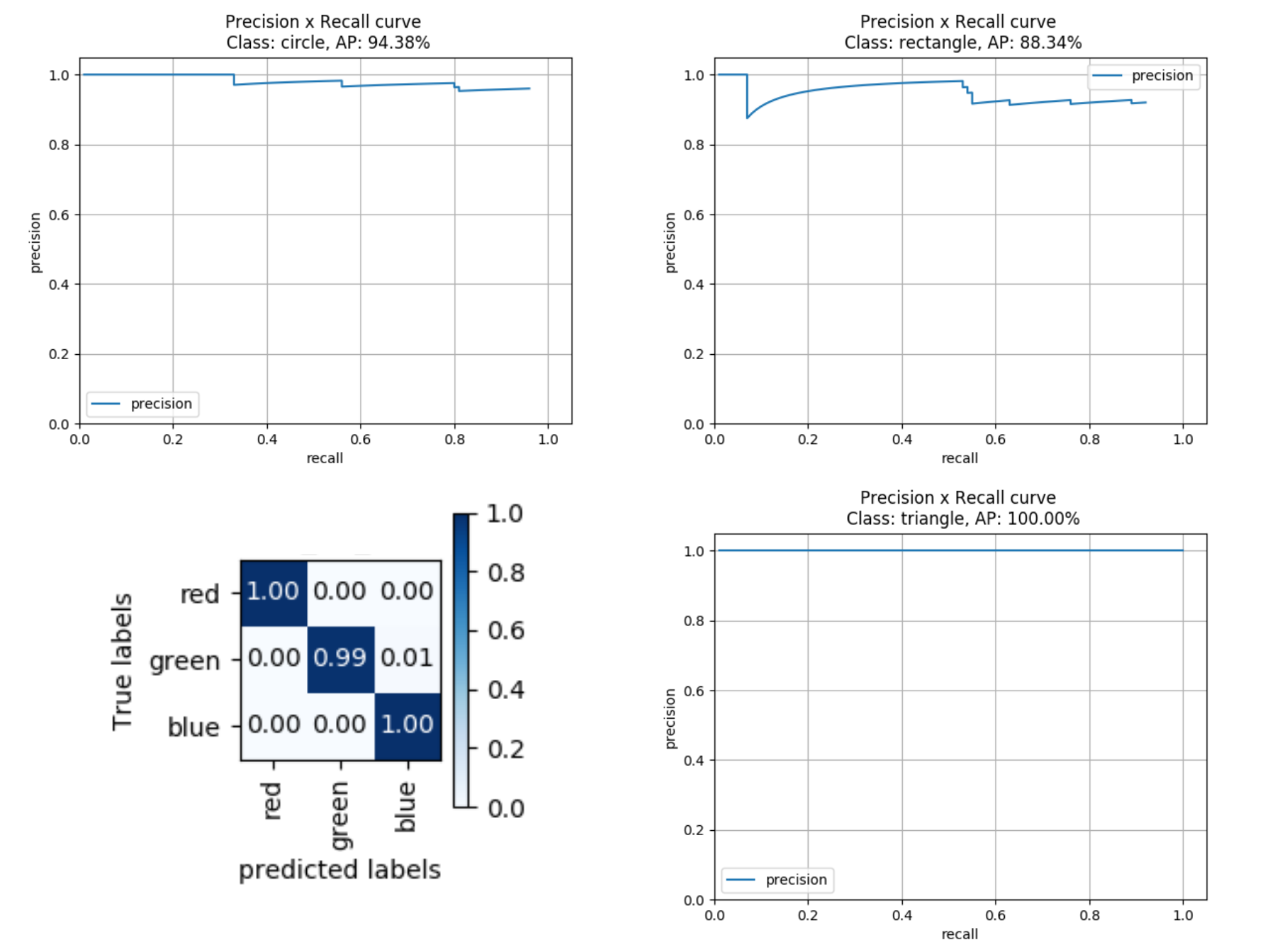
Evaluation metrics
Object detection uses mean average precision (mAP). I have adapted the algorithm for calculating mAP.
Classification uses F1 scores, precision, recall, accuracy etc. I have used sklearn and matplotlib to do the calculation and plotting.
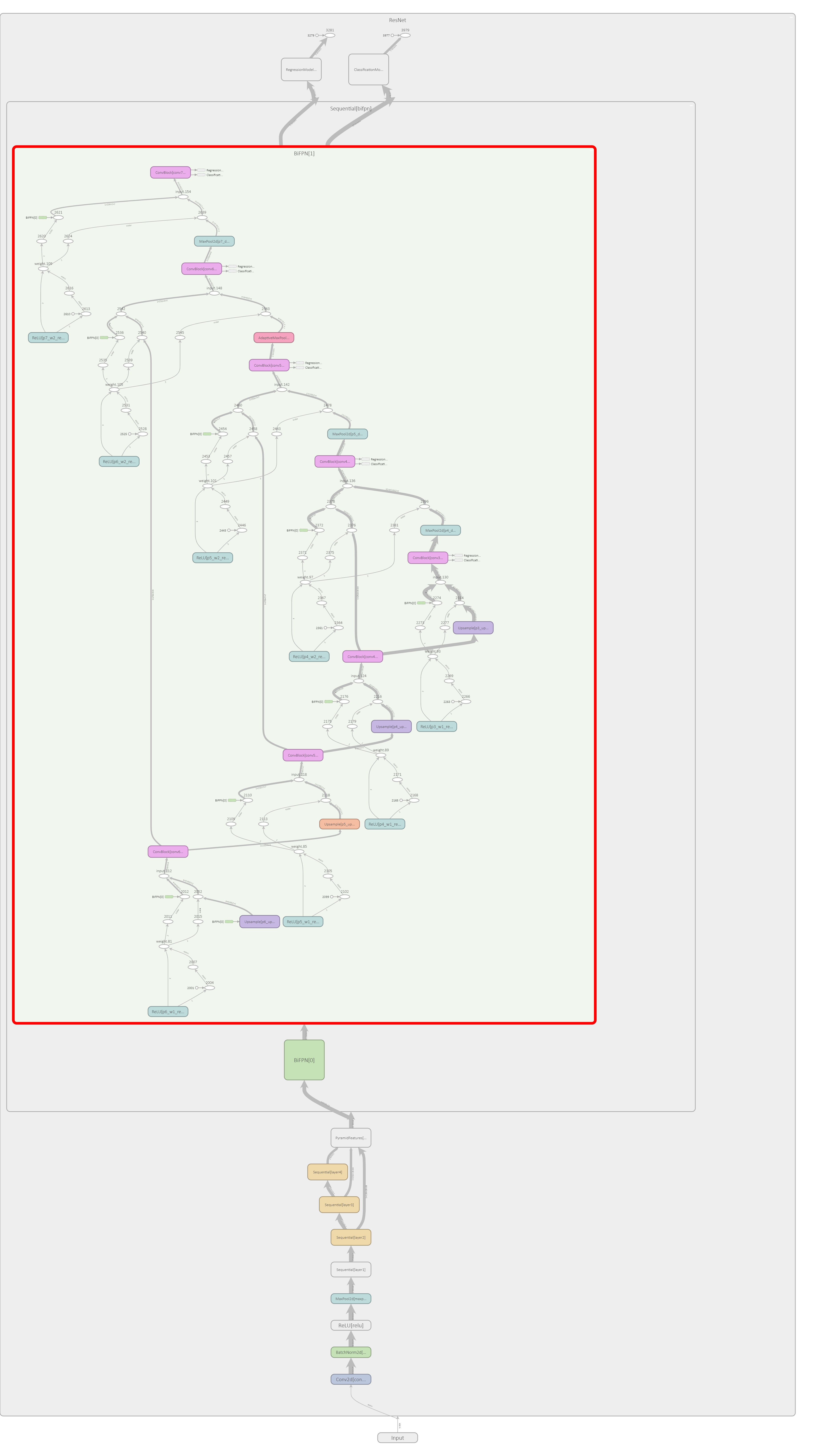
Final comments
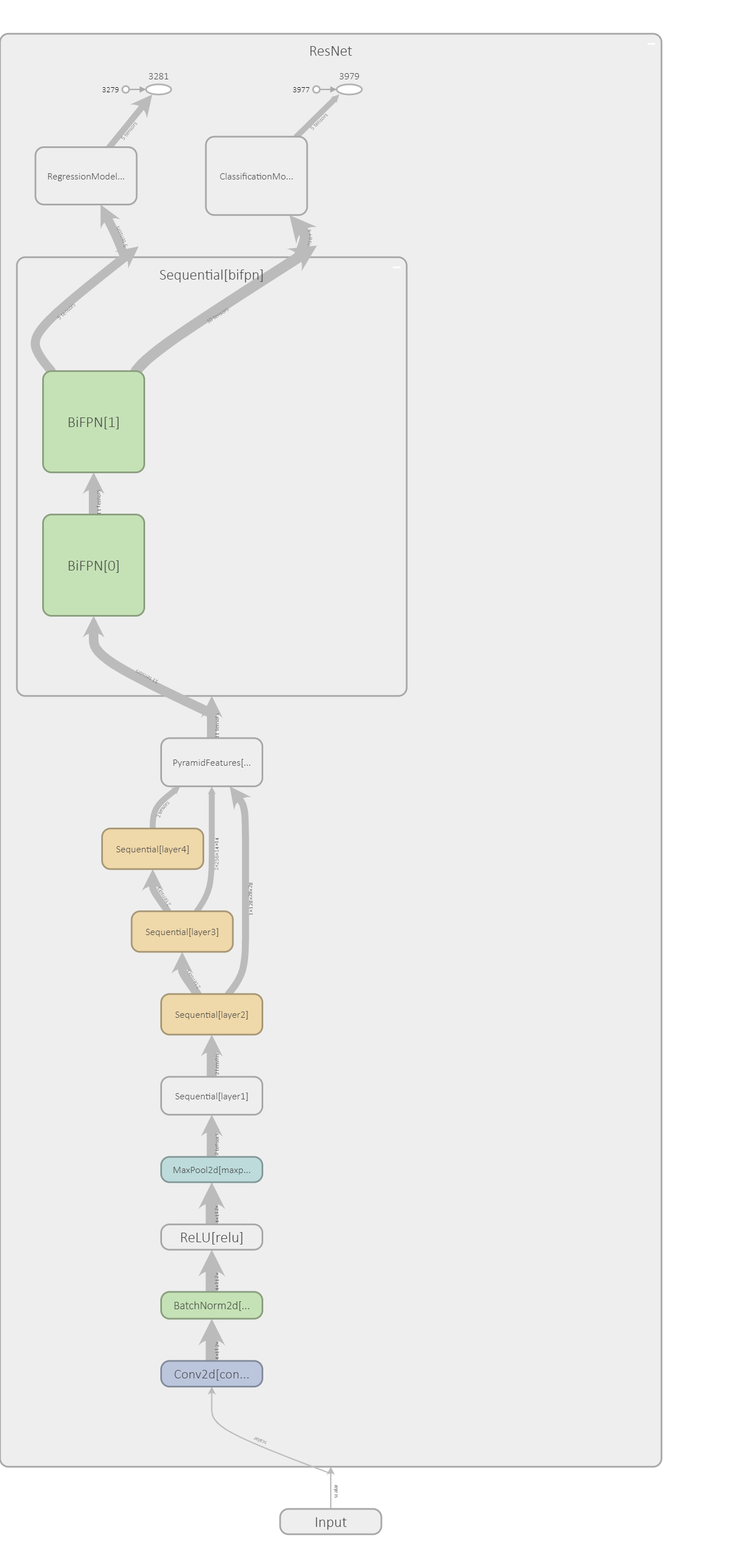
I have recently come across this paper EfficientDet: Scalable and Efficient Object Detection. My key takeaway is that it is beneficial to do more feature pyramid like processing in up- and down- directions and to combine feature maps across adjacent scale using learnable weightings. It is termed BiFPN. Some minor modification of the official implementation must be made because the dimension of the input samples of the toy dataset isn’t the same as the author’s dataset or in the power of 2. This cause dimension mismatch across the feature maps. My experience shows that there is little difference at all for this task. Understandably, this task is so trivial and easy to perform very well by RetinaNet.
import torch.nn as nn
import torch
class ConvBlock(nn.Module):
def __init__(self, num_channels):
super(ConvBlock, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(num_channels, num_channels, kernel_size=3, stride=1, padding=1, groups=num_channels),
nn.Conv2d(num_channels, num_channels, kernel_size=1, stride=1, padding=0),
nn.BatchNorm2d(num_features=num_channels, momentum=0.9997, eps=4e-5), nn.ReLU())
def forward(self, input):
return self.conv(input)
class BiFPN(nn.Module):
def __init__(self, num_channels, epsilon=1e-4):
super(BiFPN, self).__init__()
self.epsilon = epsilon
# Conv layers
self.conv6_up = ConvBlock(num_channels)
self.conv5_up = ConvBlock(num_channels)
self.conv4_up = ConvBlock(num_channels)
self.conv3_up = ConvBlock(num_channels)
self.conv4_down = ConvBlock(num_channels)
self.conv5_down = ConvBlock(num_channels)
self.conv6_down = ConvBlock(num_channels)
self.conv7_down = ConvBlock(num_channels)
# Feature scaling layers
self.p6_upsample = nn.Upsample(scale_factor=2, mode='nearest')
# self.p5_upsample = nn.Upsample(scale_factor=2, mode='nearest')
'''
becuase the toy dataset sample size is not the same as the paper,
we need to change the upsampling method to make sure the feature
maps can be concatenated.
'''
self.p5_upsample = nn.Upsample((7,7), mode='nearest')
self.p4_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p3_upsample = nn.Upsample(scale_factor=2, mode='nearest')
self.p4_downsample = nn.MaxPool2d(kernel_size=2)
self.p5_downsample = nn.MaxPool2d(kernel_size=2)
# self.p6_downsample = nn.MaxPool2d(kernel_size=2)
self.p6_downsample = nn.AdaptiveMaxPool2d((4,4))
self.p7_downsample = nn.MaxPool2d(kernel_size=2)
# Weight
self.p6_w1 = nn.Parameter(torch.ones(2))
self.p6_w1_relu = nn.ReLU()
self.p5_w1 = nn.Parameter(torch.ones(2))
self.p5_w1_relu = nn.ReLU()
self.p4_w1 = nn.Parameter(torch.ones(2))
self.p4_w1_relu = nn.ReLU()
self.p3_w1 = nn.Parameter(torch.ones(2))
self.p3_w1_relu = nn.ReLU()
self.p4_w2 = nn.Parameter(torch.ones(3))
self.p4_w2_relu = nn.ReLU()
self.p5_w2 = nn.Parameter(torch.ones(3))
self.p5_w2_relu = nn.ReLU()
self.p6_w2 = nn.Parameter(torch.ones(3))
self.p6_w2_relu = nn.ReLU()
self.p7_w2 = nn.Parameter(torch.ones(2))
self.p7_w2_relu = nn.ReLU()
def forward(self, inputs):
"""
P7_0 -------------------------- P7_2 -------->
P6_0 ---------- P6_1 ---------- P6_2 -------->
P5_0 ---------- P5_1 ---------- P5_2 -------->
P4_0 ---------- P4_1 ---------- P4_2 -------->
P3_0 -------------------------- P3_2 -------->
"""
# P3_0, P4_0, P5_0, P6_0 and P7_0
p3_in, p4_in, p5_in, p6_in, p7_in = inputs
# P7_0 to P7_2
# Weights for P6_0 and P7_0 to P6_1
p6_w1 = self.p6_w1_relu(self.p6_w1)
weight = p6_w1 / (torch.sum(p6_w1, dim=0) + self.epsilon)
# Connections for P6_0 and P7_0 to P6_1 respectively
p6_up = self.conv6_up(weight[0] * p6_in + weight[1] * self.p6_upsample(p7_in))
# Weights for P5_0 and P6_0 to P5_1
p5_w1 = self.p5_w1_relu(self.p5_w1)
weight = p5_w1 / (torch.sum(p5_w1, dim=0) + self.epsilon)
# Connections for P5_0 and P6_0 to P5_1 respectively
p5_up = self.conv5_up(weight[0] * p5_in + weight[1] * self.p5_upsample(p6_up))
# Weights for P4_0 and P5_0 to P4_1
p4_w1 = self.p4_w1_relu(self.p4_w1)
weight = p4_w1 / (torch.sum(p4_w1, dim=0) + self.epsilon)
# Connections for P4_0 and P5_0 to P4_1 respectively
p4_up = self.conv4_up(weight[0] * p4_in + weight[1] * self.p4_upsample(p5_up))
# Weights for P3_0 and P4_1 to P3_2
p3_w1 = self.p3_w1_relu(self.p3_w1)
weight = p3_w1 / (torch.sum(p3_w1, dim=0) + self.epsilon)
# Connections for P3_0 and P4_1 to P3_2 respectively
p3_out = self.conv3_up(weight[0] * p3_in + weight[1] * self.p3_upsample(p4_up))
# Weights for P4_0, P4_1 and P3_2 to P4_2
p4_w2 = self.p4_w2_relu(self.p4_w2)
weight = p4_w2 / (torch.sum(p4_w2, dim=0) + self.epsilon)
# Connections for P4_0, P4_1 and P3_2 to P4_2 respectively
p4_out = self.conv4_down(
weight[0] * p4_in + weight[1] * p4_up + weight[2] * self.p4_downsample(p3_out))
# Weights for P5_0, P5_1 and P4_2 to P5_2
p5_w2 = self.p5_w2_relu(self.p5_w2)
weight = p5_w2 / (torch.sum(p5_w2, dim=0) + self.epsilon)
# Connections for P5_0, P5_1 and P4_2 to P5_2 respectively
p5_out = self.conv5_down(
weight[0] * p5_in + weight[1] * p5_up + weight[2] * self.p5_downsample(p4_out))
# Weights for P6_0, P6_1 and P5_2 to P6_2
p6_w2 = self.p6_w2_relu(self.p6_w2)
weight = p6_w2 / (torch.sum(p6_w2, dim=0) + self.epsilon)
# Connections for P6_0, P6_1 and P5_2 to P6_2 respectively
p6_out = self.conv6_down(
weight[0] * p6_in + weight[1] * p6_up + weight[2] * self.p6_downsample(p5_out))
# Weights for P7_0 and P6_2 to P7_2
p7_w2 = self.p7_w2_relu(self.p7_w2)
weight = p7_w2 / (torch.sum(p7_w2, dim=0) + self.epsilon)
# Connections for P7_0 and P6_2 to P7_2
p7_out = self.conv7_down(weight[0] * p7_in + weight[1] * self.p7_downsample(p6_out))
return p3_out, p4_out, p5_out, p6_out, p7_out
Please feel free to play around with the code in my repository.
Reference
Parts of the code are adapted from the following resources:
- https://lilianweng.github.io/lil-log/2018/12/27/object-detection-part-4.html
- https://www.jeremyjordan.me/object-detection-one-stage/
- https://github.com/signatrix/efficientdet
- http://pjreddie.com/yolo9000/
- https://github.com/yhenon/pytorch-retinanet