
Background
Convolutional neural networks have made many advances in the field of computer vision over the past decade. One such field is the study of super resolution. There are many applications that can benefit from increasing the resolution of an image to reveal more details. For example, high resolution medical MR scan takes longer to acquire but can reveal high level of anatomical details which can be useful for medical diagnosis. In this application, the motivation is to quickly obtain low resolution MR images but super-resolve them (which hopefully could be more efficient than scanning high resolution MR images) to obtain similar level of anatomical details as in high resolution MR images. Of course, the specific motivations behind super resolution differ across domains and applications. All in all, super-resolution is helpful when obtaining high resolution images is too costly or infeasible while image quality matters. This area of research is relatively new and exciting.
General framework
In plain English, a super-resolution model is a mathematical function that takes low-resolution images and produces its high-resolution version. Because low-resolution images contain less or incomplete information to fully reconstruct them, this problem is, in theory, ill-posed.
To train a super-resolution model, we collect a dataset of high-resolution images, degrade them to mimic low-resolution images in real-world, and train a model to super resolve these image pairs. The degradation begins by applying Gaussian smoothing/ Gaussian filtering with sigma being a function of a scale factor on the high-resolution images and then down-samples (bicubic down-sampling) them to a scale factor, a value typically between 2x and 4x.
The model regards the high-resolution input images as ground truth and learns to scale the low-resolution (LR) images up to match its high-resolution images. The concept of supervised learning is portrayed in the figure below.
A variant of this concept comes from this paper, Unsupervised MRI Super-Resolution using Deep External Learning and Guided Residual Dense Network with Multimodal Image Priors.
In addition to these image pairs, the model receives high-resolution images of the same structure but from a different modality.
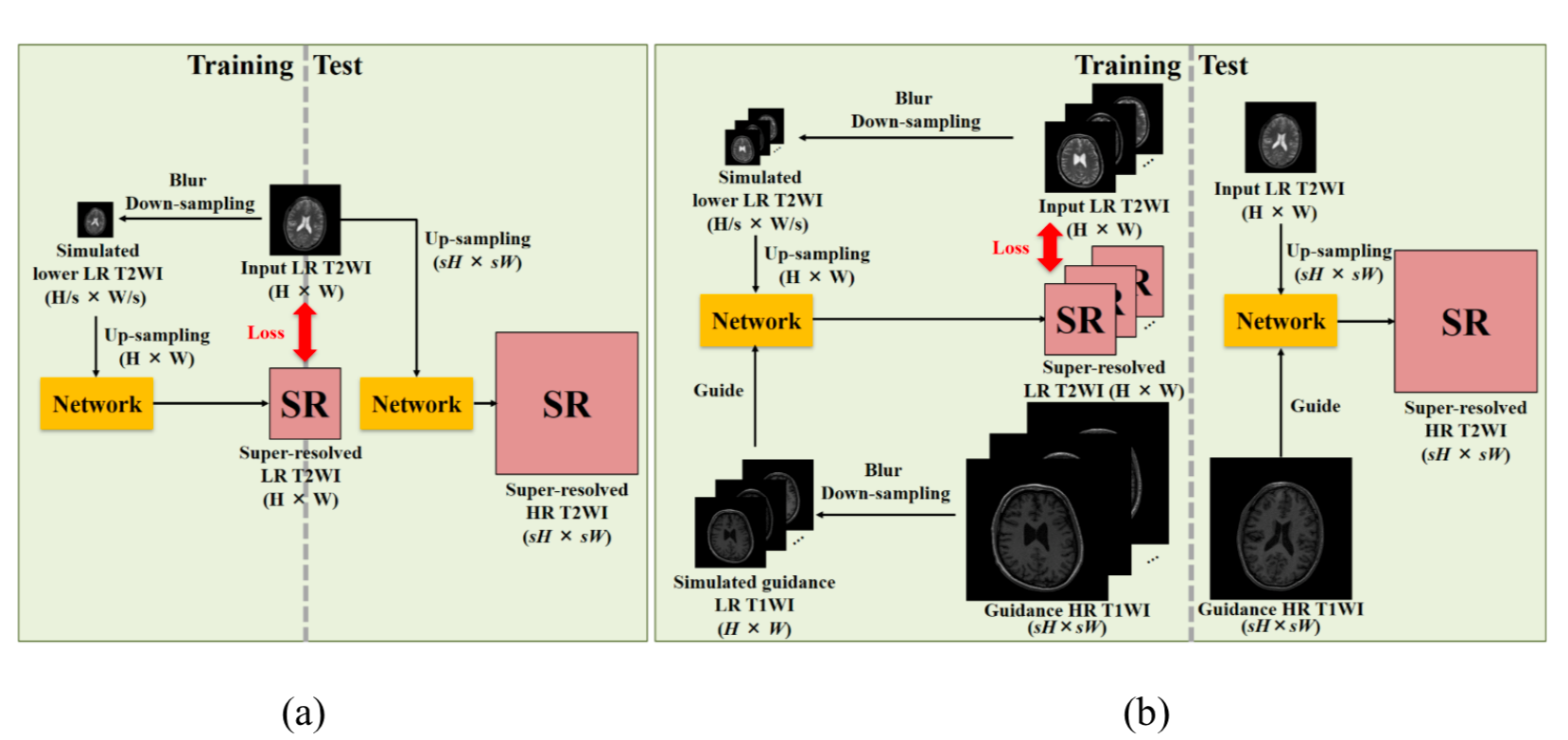
In figure (a) above, the model estimates medium-resolution images (H, W) from low-resolution images (H/s, W/s). Before handing over to the network, the low-resolution images are upsampled to (H, W) so that its resolution is on par with the final estimate that will be made by the network. The loss is calculated based on the difference of the estimates to the ground truth. During inference, the model estimates the super-resolved images (sH, sW) from up-sampled raw images (sH, sW).
In the figure (b) above, once again, the model takes in (H, W) images (from top to middle on the left-hand side) as well as the images of another modality (H, W) (from bottom to middle on the left-hand side). The intention is to use the information from multiple modalities to super resolve. One very critical factor is to have images from different modalities well aligned. During inference, the model fuses images from multiple modalities to super-resolve low resolution images from the desired modality.
Another way of looking at the general framework
A major drawback of the aforementioned framework is the degradation / down-sampling process may not necessarily reflect underlying processes that have brought about low-resolution images. By making an assumption that the degradation could be described by a fairly simple and straightforward blurring and down-sampling steps, we fail to teach a model to learn the more realistic/ real-world degradation processes. Thus, super-resolution models often perform poorly on images that are degraded by anything but straightforward smoothing and subsampling.
To tackle this issue, zero short super-resolution model has been proposed in this paper, Zero-Shot” Super-Resolution using Deep Internal Learning

Zero shot super resolution is very interesting. In figure 3, the authors use this example to illustrate the point that features in an image may not exist elsewhere and therefore are “unlearnable” for the network that are trained on millions of other unrelated images.
That idea leads us to say that the goal of the network is to learn high-resolution features from one part of the image and apply these features to super-resolve the low-resolution patches at a different image location. This idea has been used heavily in non-local means denoising techniques. Below is an example of such techniques.

How should we apply this idea in the field of super resolution?
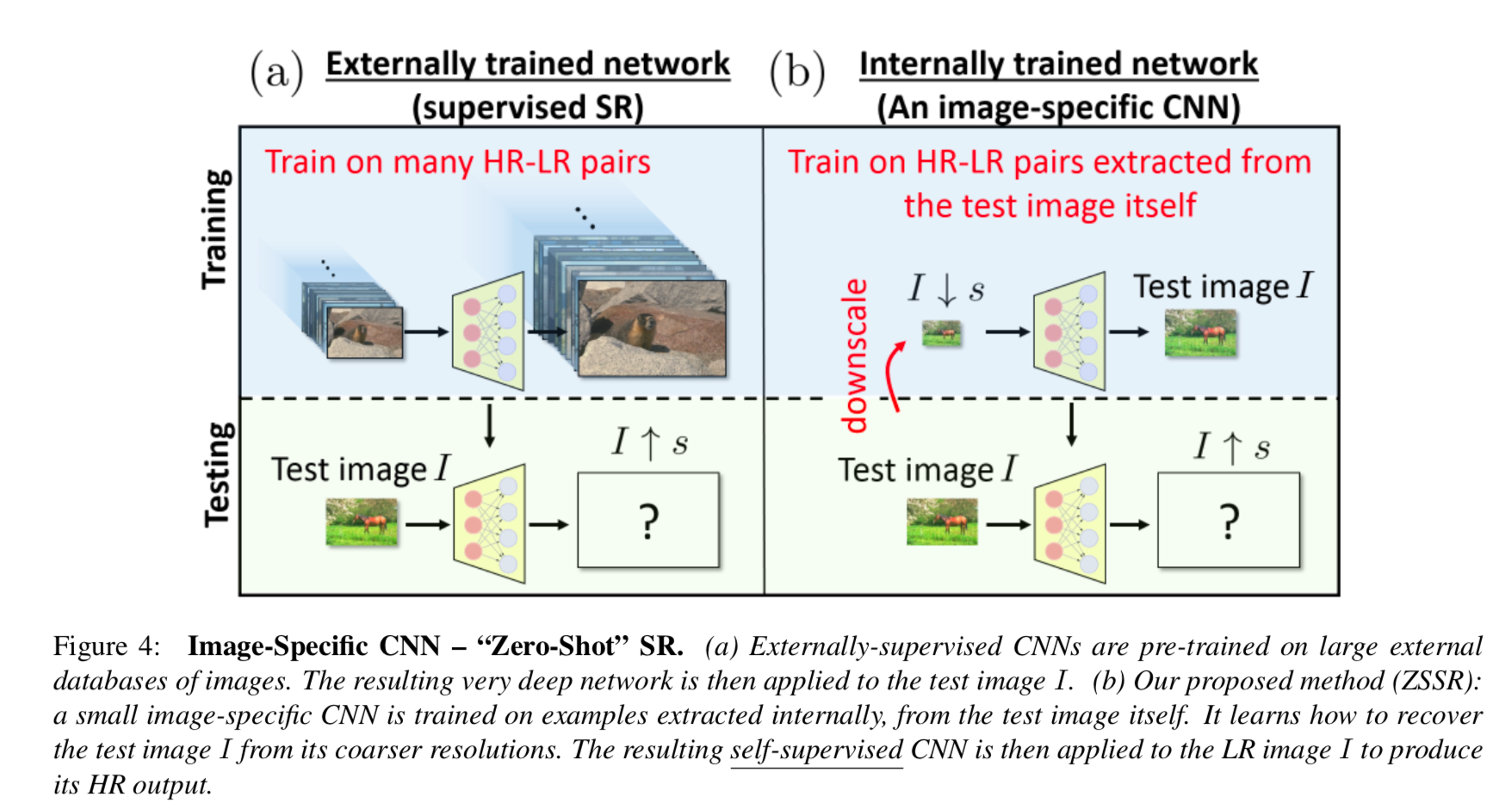
Figure 4a shows the typical paradigm found in many papers. High-resolution images are degraded by a simple down-sampling operation; a network is trained to undo this down-sampling and to increase the resolution, figuratively shown by the size of the image stacks. At test time, the model applies the same undoing operation to unknown images. Figure 4b shows the zero-shot paradigm in which training and testing use the same set of images. High resolution (HR) – low resolution (LR) pairs are created by recursively downscaling the higher resolution one to create more lower resolution samples by a fixed scaling factor, s.

What zero-shot model learns? To demonstrate what the zero-shot model has learned, Figure 5 shows an interesting property of zero shot super resolution method. When there is a high degree of self-similarity in the image, zero shot super resolution method works very well, better than the other two methods on the left. It turns out that this self-similarity is useful for “real-world” images. Figure 7 shows 3 examples that are degraded by JPEG compression, noisy and non-ideal downscaling. Although zero shot super resolution solutions are far from perfect, I think they are fairly intuitive in a sense that I would mentally draw these images in a similar fashion.

For further information, I encourage readers to find more examples from the authors’ homepage
Generative adversarial neural network as a universal degradation function
Another idea is to let a generative adversarial neural network (GAN) to approximate the unknown degradation function and therefore to undo the degradation on the images to obtain its high-resolution version. Unpaired Image Super-Resolution using Pseudo-Supervision
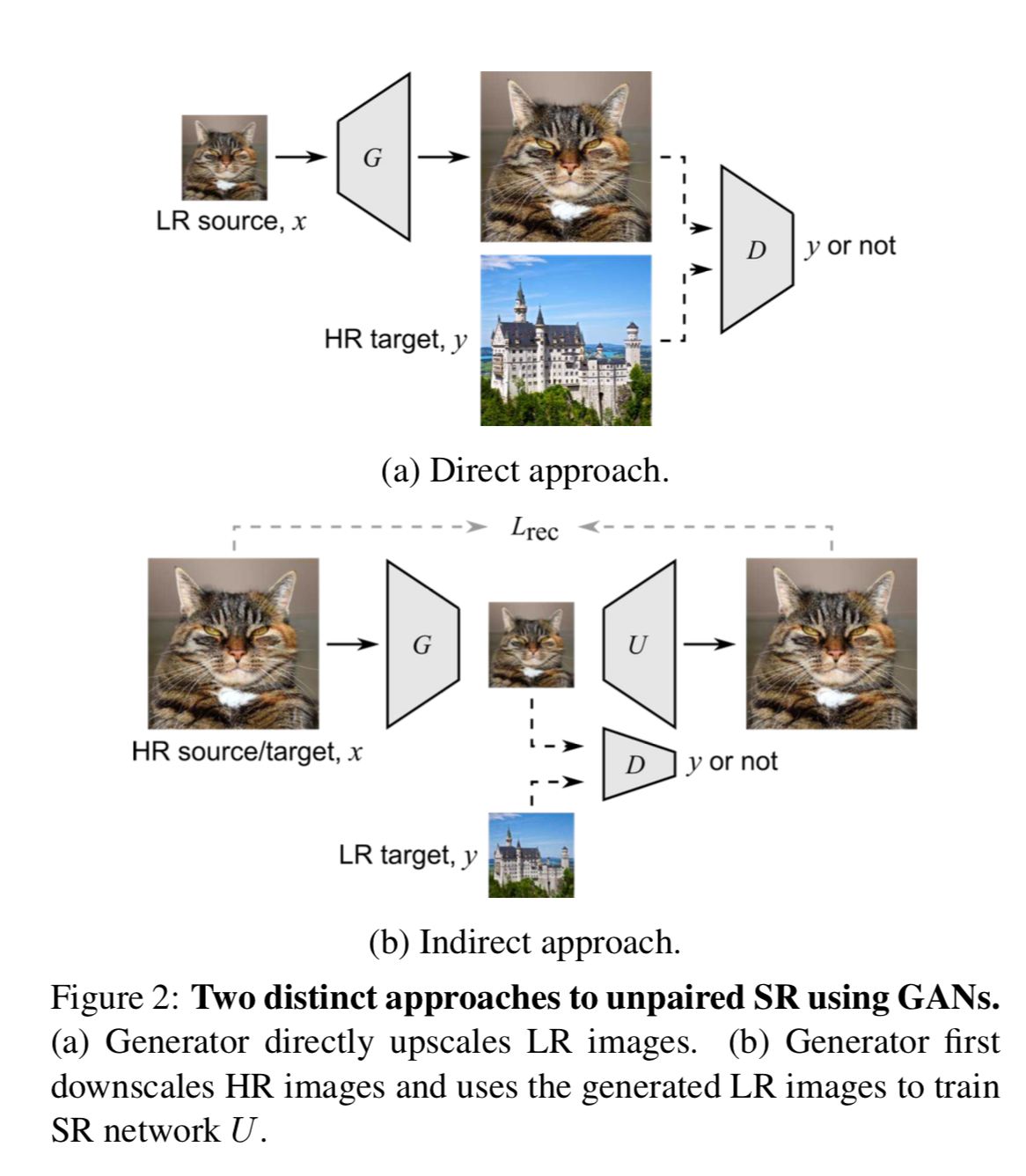
According to the authors of this paper, Unpaired Image Super-Resolution using Pseudo-Supervision, there are two main approaches on how to go about training such GANs (shown in figure 2). The direct approach is to train a generator to super-resolve images as well as to train a discriminator to distinguish whether the images are “genuine” or fake. This paradigm relies on the discriminator classification loss to optimize the generator and precludes the use of a more direct loss, a pixelwise loss between the generated images and the high-resolution ground-truth images on the generator. This loss is a major drawback in this paradigm of network training.
The indirect approach uses the generator to create degraded low-resolution images. The discriminator distinguishes the differences between the “ideal” low resolution images (ground-truth real images) and generated low resolution images. While this approach uses an up-sampling model to super resolve the low-resolution images and therefore it permits the use of pixel-wise losses, it runs into big problems as, most of the time, the “ideal” differs from “real-world” situations.
How could we use generative adversarial neural networks for super resolution?
Before diving into this proposal, let’s take a step back to review the basic of a cycle GAN in the diagram below.
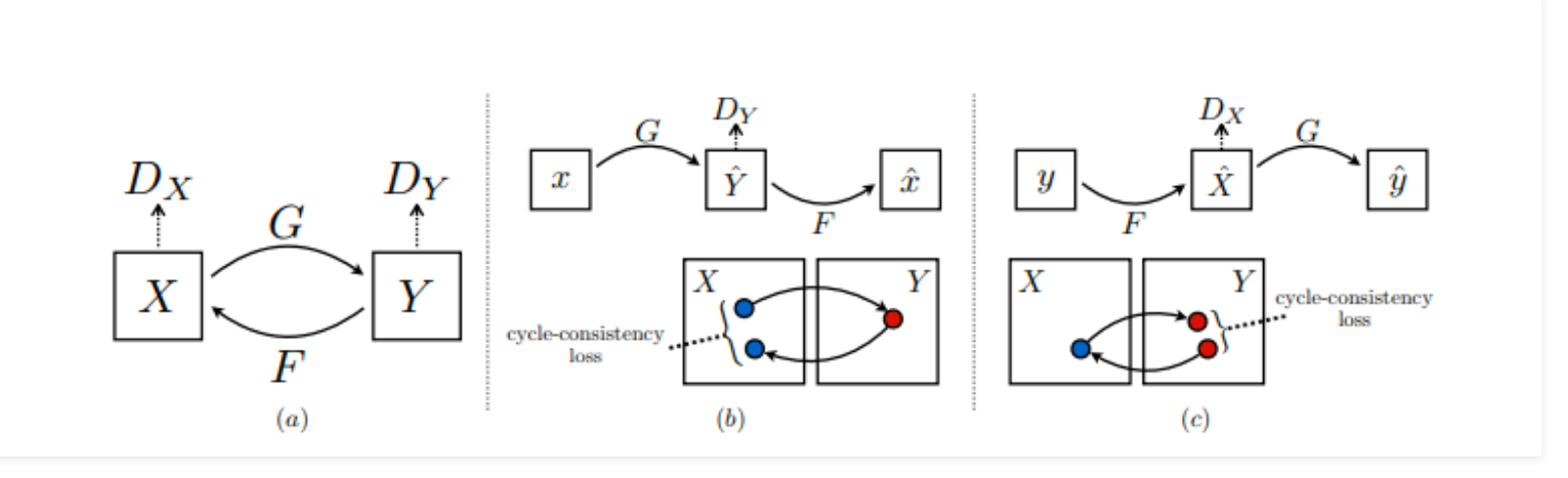
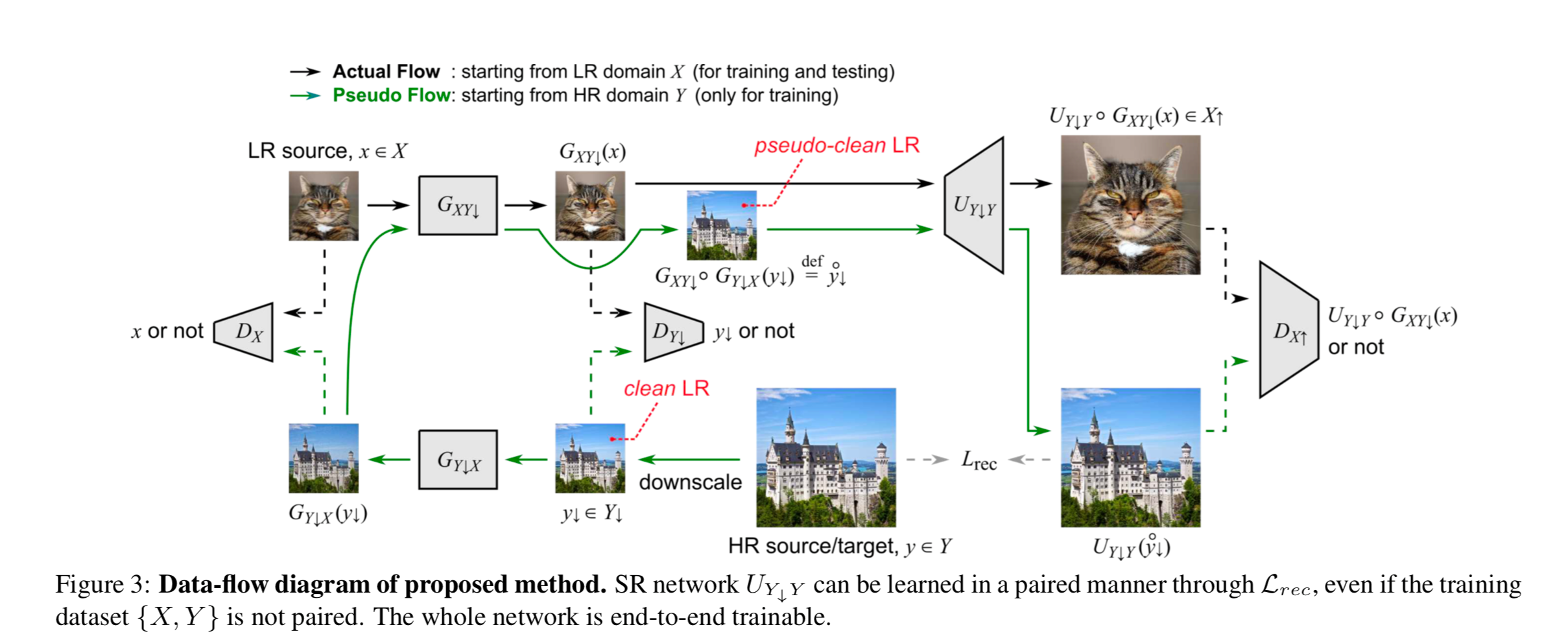
Figure 3 shows the entire framework. Please note the color of the arrow as it is extremely important to differentiate the training and testing phrases. Let’s start with the training phrase. The very first impression is that all models inside the framework are end-to-end trainable.
Adversarial losses
There are 3 discriminators Dx, Dy down and Dx up. Dx distinguishes whether the low-resolution noisy images look real and noisy. It tries to help (Gy down x) to generate realistic real-world low-resolution images. Dy down distinguishes whether clean low-resolution clean images look real and clean. The meaning of clean is that the effect of non-ideal degradation such as noise has been removed. It tries to help (Gxy down) to generate high-quality low-resolution images. Dx up distinguishes whether the high-resolution images look real and clean. It tries to help (Uy down y) to super resolve realistic features to the level of pixels.
Cycle consistency loss
Unlike the full cycle consistency loss, here the loss is calculated only from clean LR to noisy LR (Gy down x) back to clean LR or pseudo clean LR (Gxy down). The rationale is that while many different noisy images can be filtered to obtain the same clean image, it is not very required to learn to map the same clean images to their many different noisy versions.
Here are some examples of fake degraded images from a clean image:

To obtain the high-resolution images from low-resolution images, an up-sampler (Uy down y) is trained with pixelwise L1 loss.
Thus, the critical step to undo the degradation occurs only at low-resolution steps. Up-sampling is done by another model, making the division of labor quite obvious. This setup is very interesting as other papers try to do super resolution simultaneously with up-sampling.
The training (green arrow) starts from high resolution castle image. It is downscaled to create the clean low-resolution castle image. (Dy down) learns what a clean low image should look like. (Gy down x) creates a noisy version of the clean from clean. The Dx learns what a real-world noisy image should look like from a low-resolution image (cat face). Dx feedbacks how realistic the noisy images are for (Gy down x). The (Gxy down) cleans up the noisy image to produce the pseudo clean LR. (Dy down) learns the difference between the pseudo-clean and clean. This helps the (Gxy down) to be “cycle consistent” by making pseudo clean images look clean. (Uy down y) learns to super resolve the pseudo-clean LR and receives feedback via pixelwise loss. (Dx up) does not provide losses to (Uy down y). Instead, its loss goes to the other two generators.
The testing (black arrow) starts from a low noisy real-world image (cat face). (Gxy down) cleans the image to create a pseudo-clean version. This version is then super resolved by (Uy down y).
Let’s take a look at the results


This comparison of the various methods is very interesting. Note that ZZSR cannot filter out the noisy sky but the author’s proposal (ours) can.

My final thoughts:
I personally would like to see some less successful examples to get a more comprehensive understanding of the methods. However, this is a very rare practice as I have seen only very few papers have uploaded failure cases in a demonstration.
What is next?
Super resolution on videos?