
Introduction
Over the years, I have collected many quotes and idioms from famous businessmen / businesswomen, politicians, artists, actors / actresses and people from the past. As much as I would like to learn them by heart and put them into practice. From time to time, I forgot the sayings and would like to be reminded.
- Have you ever been become too lazy to read your favorite quotes on paper?
- Have you ever forgotten your favorite quotes?
- Have you ever mixed up one quote with another?
- Have you ever thought that it would be nice to have someone read it out loud to you?
Without having “someone”, I have come up with a low-cost solution: using a text-to-speech model to convert the quotes into audio files.
On the one hand, from my personal experience, Tacotron 2 and WaveGlow are powerful AI text-to-speech models. However, they fall short in reading out loud long paragraphs, pages of books, etc. There is nothing wrong with what the models speak. I feel that the speech is less coherent as it lacks the rhythm that echoes the underlying idea or the thread of the lengthy piece of writing. Without true comprehension of the author’s intention, it is rather hard to produce a fluent speech that adequately express the intended meaning.
On the other hand, quotes are special. They are short, succinct and to-the-point. These attributes make them suitable for AI text-to-speech model to read out loud.
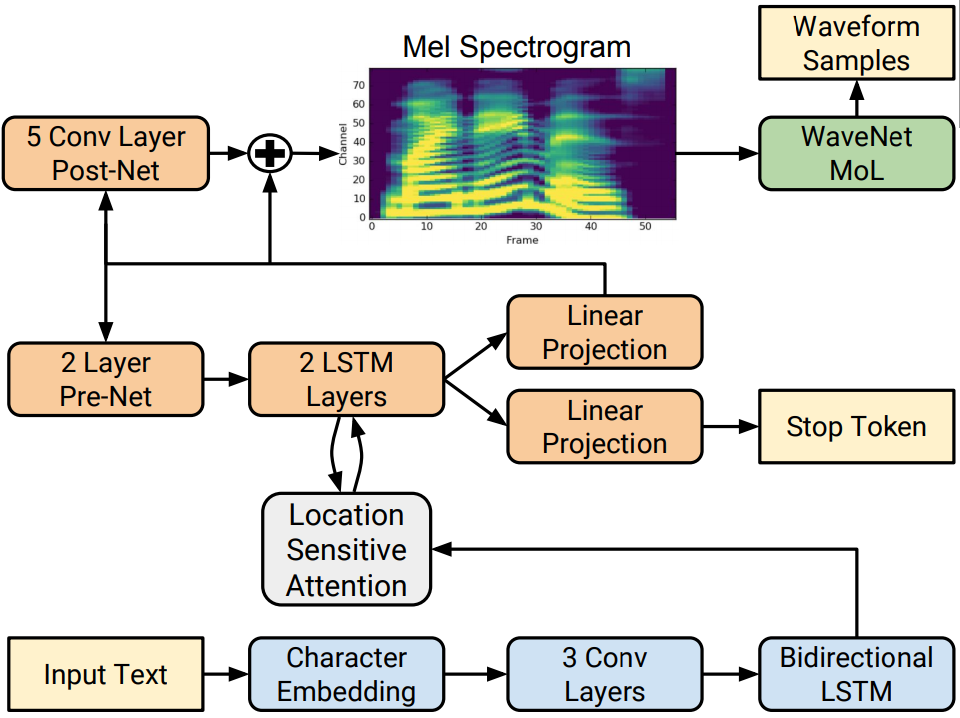
This task deploys two models in series. The first model (Tacotron 2), which converts the English text to a Mel Spectrogram sentence by sentence. The second model (WaveGlow), which converts the Mel Spectrogram to audio sound wave we can hear. To ensure quality, we also pass the audio through a denoiser.
Why Tacotron 2 and WaveGlow ?
The most important reason is that these two models are well-trained and are available (model’s checkpoints) for use from Nvidia github repository. For further details on training accuracy, validation performance, detail architectures, publications and the implementation, please visit their official repository.
Software and Hardware Prerequisites
- Nvidia GPU: GeForce 920MX
- CUDA version: 10.2
-
Driver version: 441.66
- Python: 3.7.6
- Pytorch: 1.6.0
- Scipy: 1.4.1
Methods
-
Read in the quotes, which are stored in a text file in Unicode/ UTF- 8 (Python 3 standard) I put 10 quotes from Warren Buffett in this example to show how the pipeline can be made to work. Samples here !
-
Load Tacotron 2 and WaveGlow. I keep the default setting for these two models. However, due to the GPU memory constrains, I could not fit WaveGlow model on the GPU. Thus, Tacotron 2 runs on the GPU while WaveGlow runs on the CPU. The ramification is that inference is pretty slow at the WaveGlow side.
-
Convert every single word in the quote to word embedding (the model uses long integers to do that). Set the maximum sentence’s length. The Tacotron 2 works on consistent sentence length within a batch. We fill the shorter sentences with zero at the end (padding), so that every sentence looks equal in length for Tacotron 2. Tacotron 2 predicts the quote its Mel spectrogram.
-
Create the Mel spectrogram to audio sound waves Note that the Mel spectrogram is now sitting on the GPU while WaveGlow is on the CPU. We transfer the data across the devices so that WaveGlow can predict the audio wave from the Mel spectrogram. Finally, we lower noise in the audio waves with the denoiser. Note the audio is an numpy array. Often we can control the loudness of the clip by lower or raising the amplitude. However, WaveGlow usually picks a good loudness level so that manual intervention is really unnecessary.
-
Save the audio file to disk. Scipy wavfile can write the numpy array into a WAV audio file.
Results
Individual quote and audio
We simply attempt to be fearful when others are greedy and to be greedy only when others are fearful.
It takes 20 years to build a reputation and five minutes to ruin it. If you think about that, you’ll do things differently.
Price is what you pay. Value is what you get.
Someone’s sitting in the shade today because someone planted a tree a long time ago.
Rule Number 1: Never lose money. Rule Number 2: Never forget Rule Number 1.
Risk comes from not knowing what you’re doing.
It’s only when the tide goes out that you discover who’s been swimming naked.
It’s far better to buy a wonderful company at a fair price than a fair company at a wonderful price.
Our favorite holding period is forever.
It’s better to hang out with people better than you. Pick out associates whose behavior is better than yours and you’ll drift in that direction.
Create an app that plays your favorite quotes
Pain point: It is inconvenient to play and read each quote manually even though we have an AI read it out loud to us. To lower the effort and to improve the ease of learning, I have create an app that plays the quotes randomly and repeatedly, so that we can listen to them non-stop anywhere and anytime. Of course we can terminate the app once we have mastered the hidden gem in them and put them to work in practice.
The goal of the app is to play the quote audio files and display the accompanied texts synchronously.
The app should play the quotes in random yet sequential order indefinitely.
To achieve the above, I use Pygame to create a “game” that loops through the quotes and their audio indefinitely in a randomly generated order. Pygame is very handy for this task as it provides a rich library of API for handling graphics, user’s inputs, sounds and more. Most importantly, it is easy to use. Of course, other GUI libraries such as Tkinter can also be used instead.
For more details: Please visit Create a Python Quote Player
Here is a short demo.
Enjoy and Happy learning. Please feel free to send me your favorite quotes or other suggestions.
Python Scripts
Generating audio on quotes
Here I provided the adaptation I made to make use of Tacotron and WaveGlow. For the full information on the models, please visit their official repository.
Set up Tacotron and WaveGlow
from tacotron2.text import text_to_sequence
import models, os
import torch, logging
import argparse
import numpy as np
from scipy.io.wavfile import write
import matplotlib
import matplotlib.pyplot as plt
import sys
import time
from waveglow.denoiser import Denoiser
from inference import checkpoint_from_distributed, unwrap_distributed,\
handle_input_text, prepare_input_sequence, MeasureTime
def get_tacotron_config():
model_name = 'Tacotron2'
model_config = {'mask_padding': False, 'n_mel_channels': 80, 'n_symbols': 148,
'symbols_embedding_dim': 512, 'encoder_kernel_size': 5,
'encoder_n_convolutions': 3, 'encoder_embedding_dim': 512,
'attention_rnn_dim': 1024, 'attention_dim': 128,
'attention_location_n_filters': 32,
'attention_location_kernel_size': 31,
'n_frames_per_step': 1,
'decoder_rnn_dim': 1024, 'prenet_dim': 256,
'max_decoder_steps': 2000, 'gate_threshold': 0.5,
'p_attention_dropout': 0.1, 'p_decoder_dropout': 0.1,
'postnet_embedding_dim': 512, 'postnet_kernel_size': 5,
'postnet_n_convolutions': 5, 'decoder_no_early_stopping': False}
cpu_run, forward_is_infer = False, True
checkpoint = 'checkpoints/tacotron2_1032590_6000_amp'
return model_name, model_config, cpu_run, forward_is_infer, checkpoint
def get_waveGlow_config():
model_name = 'WaveGlow'
model_config = {'n_mel_channels': 80, 'n_flows': 12, 'n_group': 8,
'n_early_every': 4, 'n_early_size': 2,
'WN_config': {'n_layers': 8, 'kernel_size': 3, 'n_channels': 256}}
checkpoint = 'checkpoints/waveglow_1076430_14000_amp'
cpu_run, forward_is_infer = True, True
return model_name, model_config, cpu_run, forward_is_infer, checkpoint
def load_and_setup_model(model_name, model_config, cpu_run, forward_is_infer, checkpoint, fp16_run):
model = models.get_model(model_name, model_config, cpu_run=cpu_run,
forward_is_infer=forward_is_infer)
if checkpoint is not None:
if cpu_run:
state_dict = torch.load(checkpoint, map_location=torch.device('cpu'))['state_dict']
else:
state_dict = torch.load(checkpoint)['state_dict']
if checkpoint_from_distributed(state_dict):
state_dict = unwrap_distributed(state_dict)
model.load_state_dict(state_dict)
if model_name == "WaveGlow":
model = model.remove_weightnorm(model)
model.eval()
if fp16_run:
model.half()
print (model_name , ' loaded')
return model
class Speaker(object):
def __init__(self):
self.denoising_strength=0.01
self.sigma_infer=0.9
model_name, model_config, cpu_run, forward_is_infer, checkpoint = get_tacotron_config()
tacotron2 = load_and_setup_model(model_name, model_config, cpu_run, forward_is_infer, checkpoint, False)
model_name, model_config, cpu_run, forward_is_infer, checkpoint = get_waveGlow_config()
waveglow = load_and_setup_model(model_name, model_config, cpu_run, forward_is_infer, checkpoint, False)
denoiser = Denoiser(waveglow)
# if not args.cpu:
# denoiser.cuda()
jitted_tacotron2 = torch.jit.script(tacotron2)
self.denoiser = denoiser
self.tacotron = jitted_tacotron2
self.waveglow = waveglow
def get_audio(self, sequences_padded, input_lengths, logger):
measurements = {}
with torch.no_grad(), MeasureTime(measurements, "tacotron2_time", cpu_run=False):
mel, mel_lengths, alignments = self.tacotron(sequences_padded, input_lengths)
with torch.no_grad(), MeasureTime(measurements, "waveglow_time", cpu_run=True):
audios = self.waveglow(mel.cpu(), sigma=self.sigma_infer)
audios = audios.float()
with torch.no_grad(), MeasureTime(measurements, "denoiser_time", cpu_run=True):
audios = self.denoiser(audios, strength=self.denoising_strength).squeeze(1)
logger.info("Stopping after " + str(mel.size(2)) +" decoder steps")
tacotron2_infer_perf = mel.size(0)*mel.size(2)/measurements['tacotron2_time']
waveglow_infer_perf = audios.size(0)*audios.size(1)/measurements['waveglow_time']
logger.info('tacotron2_infer_perf {}'.format(tacotron2_infer_perf))
logger.info('measurements {}'.format(measurements))
logger.info('waveglow_infer_perf {}'.format(waveglow_infer_perf))
return audios, mel_lengths
Inference
def prepare_input_sequence(texts, cpu_run=False):
assert isinstance(texts, list)
d = []
for i,text in enumerate(texts):
print ('text ', text)
d.append(torch.IntTensor(
text_to_sequence(text, ['english_cleaners'])[:]))
text_padded, input_lengths = pad_sequences(d)
if not cpu_run:
text_padded = text_padded.cuda().long()
input_lengths = input_lengths.cuda().long()
else:
text_padded = text_padded.long()
input_lengths = input_lengths.long()
return text_padded, input_lengths
def remove_empty_lines(x):
return [i for i in x if len(i) > 1]
def handle_input_text(path):
texts = []
try:
with open(path, 'r', encoding='utf-8') as f:
texts = f.readlines()
except Exception as e:
print("Could not read file")
print (e)
sys.exit(1)
texts = remove_empty_lines(texts)
if len(texts) == 0:
raise ValueError('This text file is empty!')
print ('texts {}'.format(texts))
return texts
def pad_sequences(batch):
input_lengths = [len(i) for i in batch]
max_input_len = max(input_lengths)
text_padded = torch.LongTensor(len(batch), max_input_len)
text_padded.zero_()
for i, text in enumerate(batch):
text_padded[i, :text.size(0)] = text
return text_padded, torch.Tensor(input_lengths)
Main script
from tacotron2.text import text_to_sequence
import models, os
import torch, logging
import argparse
import numpy as np
from scipy.io.wavfile import write
import matplotlib
import matplotlib.pyplot as plt
import sys
import time
from waveglow.denoiser import Denoiser
from inference import checkpoint_from_distributed, unwrap_distributed, handle_input_text, prepare_input_sequence, write
from txt_to_speech import Speaker
def start_logging():
log_dir =
fh = logging.FileHandler(os.path.join(log_dir, 'quotes.log'), 'w')
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
# handler = logging.StreamHandler() # only for console display
bf = logging.Formatter('{asctime} {name} {levelname:8s} {message}',
style='{')
# handler.setFormatter(bf)
fh.setFormatter(bf)
logger.addHandler(fh)
# logger.addHandler(handler)
return logger
def pad_zero(x):
target_len = 4
sx = str(x)
current_len = len(sx)
padding = target_len - current_len
if padding > 0:
return ''.join(['0'] * padding) + sx
else:
return sx
if __name__ == "__main__":
logger = start_logging()
# logger.debug('This is a DEBUG message')
speaker = Speaker()
input_dir =
tag = 'quotes'
folders = [folder for folder in os.listdir(input_dir) if os.path.isdir(os.path.join(input_dir, folder)) ]
files = [(folder, file) for folder in folders for file in os.listdir(os.path.join(input_dir, folder)) if tag in file]
# files = [(folder, file) for folder in os.listdir(input_dir) for file in os.listdir(os.path.join(input_dir, folder)) if 'wav' in file]
# for folder, file in files:
# os.remove(os.path.join(input_dir, folder, file))
total = len(files)
logging.info('len(files) {}'.format(total))
stft_hop_length=256
sampling_rate=22050
OVERWRITE = False
logging.info('OVERWRITE : {}'.format(OVERWRITE))
page_number_code = 0
for k, (folder, file) in enumerate(files):
# page_number = file.split(tag)[0][::-1].split('_')[0]
# page_number_code = 1000 * int(page_number)
txt_path = os.path.join(input_dir, folder, file)
texts = handle_input_text(txt_path)
logging.info('{} out of {} folder {}, file {}'.format(k, total, folder, file))
logging.info('txt_path {}'.format(txt_path))
total_lines = len(texts)
for i, text in enumerate(texts):
page_number_code_zero = pad_zero(page_number_code + i)
output_filename = folder + '_'+ page_number_code_zero + '.wav'
output_path = os.path.join(input_dir, folder, output_filename)
if not os.path.exists(output_path) or OVERWRITE:
text = [text] # list format
sequences_padded, input_lengths = prepare_input_sequence(text, cpu_run=False)
print ('sequences_padded {}, input_lengths {}'.format(sequences_padded, input_lengths))
# print (output_filename, page_number, file)
audios, mel_lengths = speaker.get_audio(sequences_padded, input_lengths, logger)
# audios = ['a']
for j, audio in enumerate(audios):
# write(output_path, sampling_rate, np.random.rand(10*sampling_rate))
# plt.imshow(alignments[i].float().data.cpu().numpy().T, aspect="auto", origin="lower")
# figure_path = args.output+"alignment_"+str(i)+"_"+args.suffix+".png"
# plt.savefig(figure_path)
audio = audio[:mel_lengths[j]*stft_hop_length]
audio = audio/torch.max(torch.abs(audio))
write(output_path, sampling_rate, audio.cpu().numpy())
logging.info('{} out of {} audio done'.format(i, total_lines))
else:
logging.info('Already DONE')
Building and running the app
The app displays the quotes (queued up) along with their audio files in distinguishable manner.
import os
import pygame , time
from app_tools import *
import random
import itertools
# from math import pi
if __name__ == "__main__":
pygame.init()
pygame.display.set_caption("Play favorite quotes")
# done variable is using as flag
done = False
clock = pygame.time.Clock()
#load the fonts
# font = pygame.font.SysFont("Times new Roman", 24)
font = pygame.font.SysFont("Calibri", 24)
# Render background image in new surface
img = pygame.image.load('Warren-Buffett-cash-share-market-buy-GFC-profit-investors-stocks.jpg')
rect = img.get_rect()
size = list(img.get_rect().size)
screen = pygame.display.set_mode(size)
img.convert()
counter = 0
start = True
pause = False
lines, audio_dict, num_quotes = collect_inputs()
loop_mode = 'forever'
play_mode = 'shuffle'
master_index = list(range(num_quotes)) # holder, use for shuffle later on
if play_mode == 'shuffle':
random.shuffle(master_index)
while not done:
# clock.tick() limits the while loop to a max of 10 times per second.
clock.tick(10)
for event in pygame.event.get(): # User did something
if event.type == pygame.QUIT: # If user clicked on close symbol
done = True # done variable that we are complete, so we exit this loop
if event.type == pygame.KEYDOWN:
if event.key == pygame.K_SPACE:
if not pause:
pause = True
print ('pause.......')
else:
pause = False
print ('resume.......')
'''
be very careful; don't put this inside the event loop
event loop somehow awaiting for something.... very laggy
'''
if start:
sound_effect = pygame.mixer.Sound(audio_dict[master_index[counter]])
duration = sound_effect.get_length()
start_time = time.time()
sound_effect.play()
if pause:
# pygame.mixer.pause()
sound_effect.stop()
else:
pygame.mixer.unpause()
start = False
if (time.time() - start_time) > duration:
start = True
counter += 1
if counter == num_quotes:
if loop_mode != 'forever':
done = True
else:
if play_mode == 'shuffle':
random.shuffle(master_index)
counter = 0
start = True
# All drawing code occurs after the for loop and but
# inside the main while done==False loop.
screen.blit(img, rect)
display_quotes = counter
last_y = size[0] * 0.05
margin_x = size[1]* 0.05
while last_y < size[0]* 0.5 and display_quotes < num_quotes:
if display_quotes == counter:
color=pygame.Color('white')
bold = True
else:
color=pygame.Color('pink')
bold = False
font.set_bold(bold)
last_y = blit_text(screen, str(display_quotes)+' : ' + lines[master_index[display_quotes]],
(margin_x,last_y), font, color)
display_quotes += 1
pygame.display.flip()
# Quite the execution when clicking on close
pygame.quit()
Formating and I/O
import os
import pygame , time
def blit_text(surface, text, pos, font, color=pygame.Color('black')):
words = [word.split(' ') for word in text.splitlines()] # 2D array where each row is a list of words.
space = font.size(' ')[0] # The width of a space.
max_width, max_height = surface.get_size()
max_width /= 2.5
x, y = pos
for line in words:
for word in line:
word_surface = font.render(word, True, color)
word_width, word_height = word_surface.get_size()
if x + word_width >= max_width:
x = pos[0] # Reset the x.
y += word_height # Start on new row.
surface.blit(word_surface, (x, y))
x += word_width + space
x = pos[0] # Reset the x.
y += word_height # Start on new row.
return y
def collect_inputs():
with open(, 'r') as f:
lines = f.readlines()
lines = [line for line in lines if len(line) > 3]
lines = {i:line for i, line in enumerate(lines)}
audio_path =
audio = [file for file in os.listdir(audio_path) if file.endswith('.wav')]
audio_dict = {int(file.split('_')[-1].rstrip('.wav')):os.path.join(audio_path, file) for file in audio}
num_quotes = len(audio_dict)
assert len(audio_dict) == len(lines)
print ('{} quotes and sound files loaded.'.format(num_quotes))
return lines, audio_dict, num_quotes