
This article details my learning of a new, emerging and very interesting technology in recent years. No, it isn’t Large Language Model. It is Gaussian Splatting and Neural Radiance Field. A technology I think has the potential to change our way of creating digital assets in future.
What is Neural Radiance Field?
Neural Radiance Field (NeRF) is an advanced technique in computer vision that creates detailed 3D scenes from a set of 2D photos taken from different angles. Imagine you take many pictures of a place or object, and NeRF learns how light interacts with the surfaces in that scene. It uses a special kind of artificial intelligence called a neural network to understand both the shape and appearance of everything in the scene.
The neural network takes as input the position in 3D space and the direction you are looking from and predicts the color and density at that point. By doing this for many points along imaginary camera rays through the scene, NeRF can generate realistic images from new viewpoints that were not part of the original photos. from the research literature, we have discover that when the network takes in a plain vanilla input of XYZ coordinates and the viewing directions, the network fails to learn or generalize the geometry of the scene. A better approach is to transform the XYZ coordinates and the viewing directions with high frequency Fourier transform (sine / cosine transform). That is, by embedding or encoding the low frequency spatial signal in a high frequency domain. This higher frequencies matches the structure of this type of neural network architecture (often a Multilayer Perceptron, MLP). A theory that is supported in Neural Tangent Kernel Research. Therefore, the MLP can learn a continuous / non-linear volume representation.
Along with faithfully reproducing the assets’ geometry and property, what really makes NeRF special is its ability to recreate complex lighting effects like reflections and transparency, producing photo-realistic 3D views. This process involves training a neural network to become a continuous function that models both geometry and how light behaves based on the input images. This ability is particularly important to those who would like to generate photo-realistic images from any arbitrary viewpoints under a similar lighting conditions without explicitly modelling a mesh.
NeRF has many applications including virtual reality, gaming, medical imaging, robotic vision, and satellite mapping for urban planning of smart cities, where generating accurate 3D models from photos is essential. It allows seeing a scene from any angle with incredible detail and realistic lighting without needing complex physical models or extra hardware beyond a set of photos
What is Gaussian Splatting?
Gaussian Splatting in computer vision is a modern technique used to create detailed 3D models of scenes from multiple photos or videos. Imagine you have many pictures of an object or place taken from different angles. Gaussian Splatting takes these images and first creates a rough 3D point cloud—a collection of points that represent the shape of the scene. Then, instead of simply using points, each point is transformed into a tiny 3D ellipsoid, called a Gaussian splat, that can be stretched, colored, and made semi-transparent.
These Gaussian splats act like small, fuzzy blobs that together form an accurate and smooth 3D representation of the scene. The method then optimizes these blobs’ positions, sizes, colors, and transparency to best match the original images.
The splats undergo an optimization process that adjusts their parameters to minimize the difference between rendered images from splats and the original input images. This process uses differentiable rasterization for projecting splats onto a 2D image plane, loss functions to measure image differences, and optimization algorithms to fine-tune the splats. Adaptive control may add or remove splats to maintain detail where necessary. Finally, the splats are projected onto a 2D screen to render realistic views of the scene from any angle in real time.
Splatting is a rendering technique used in computer graphics where instead of rendering traditional geometric primitives like triangles. Each splat corresponds to a localized region of the scene, essentially forming a fuzzy or blurred footprint in the image space. During rendering, these splats are projected onto the 2D screen and composited together to form a final image. Because splats are volumetric and translucent, they can effectively represent complex shapes, surfaces, and lighting effects without the need for explicit meshes.
In the context of Gaussian Splatting for 3D reconstruction, each Gaussian splat is a small 3D ellipsoid described by parameters such as position, shape, orientation, color, and transparency. This volumetric approach allows smooth blending of splats, capturing fine scene details and complex light interactions.
During training or preprocessing, the Gaussian splats are sorted in a specific order, typically along the viewing direction or depth from the camera perspective. This sorting is crucial because rendering involves compositing splats back-to-front (or using other blending techniques like alpha blending) to correctly accumulate color and transparency information. Pre-sorting enables the renderer to quickly traverse the splats in the correct order during image synthesis, thereby accelerating rendering time considerably.
Unlike Neural Radiance Fields (NeRF), Gaussian Splatting does not rely on heavy, layered neural networks, so it can achieve lightning-fast training and real-time rendering by leveraging its precomputed sort order to efficiently composite splats, enabling real-time rendering of new images from arbitrary viewpoints. It produces highly detailed, photorealistic 3D reconstructions with complex lighting and reflections, suitable for real-time applications where speed, quality and efficiency are crucial. The method excels in rendering quality and efficiency, producing smooth, seamless models from raw images or videos. Hence, what makes Gaussian Splatting special is that it produces highly detailed and photorealistic 3D renderings without relying on complex neural networks which is the speed bottleneck in real world practice.
What is COLMAP?
COLMAP is a widely-used computer vision software that reconstructs 3D models from overlapping photos by detecting and matching keypoints across images that are scale invariant. It estimates the cameras’ intrinsic parameters (internal characteristics like focal length and optical center) and extrinsic parameters (position and orientation relative to the scene) through Structure-from-Motion (SfM) and then generates dense 3D reconstructions through Multi-View Stereo (MVS).
Camera Models in 3D Reconstruction
Camera models mathematically describe how 3D points in the world are projected onto a 2D image plane. The most common is the pinhole camera model, which assumes an idealized camera with a single point through which light rays pass (the optical center) and an image plane where the scene is projected.
The key mathematical concept involves projecting a 3D point
\[P_W = (X, Y, Z, 1)^T\]in homogeneous world coordinates to a 2D point \(p = (x, y, 1)^T\) on the image plane using a projection matrix \(\mathbf{M}\) that combines intrinsic and extrinsic parameters:
\[p = \mathbf{M} P_W = \mathbf{K} [\mathbf{R} \mid \mathbf{t}] P_W\]Where:
- \(\mathbf{K}\) is the intrinsic matrix encoding the focal length \(f\), skew, and principal point \((c_x, c_y)\):
- \(\mathbf{R}\) is a \(3 \times 3\) rotation matrix representing the camera orientation.
- \(\mathbf{t}\) is a translation vector representing the camera position in the world.
The extrinsic parameters \((\mathbf{R}, \mathbf{t})\) describe the transformation from world coordinates to the camera coordinate system.
This projection involves a nonlinear division by depth (the \(Z\) coordinate in camera space), which results in perspective effects like objects appearing smaller when they are farther away.
COLMAP’s Role
COLMAP estimates these intrinsic \(\mathbf{K}\) and extrinsic \(\mathbf{R}, \mathbf{t}\) parameters by feature matching and optimizing reprojection error, enabling accurate mapping between 3D points and image pixels. This camera model forms the basis for subsequent 3D reconstruction using point clouds, meshes, or volumetric representations like NeRF and Gaussian Splatting.
Put this in layman term, COLMAP allows us to set a camera model (a math equation that describes our smart phone camera for example). Then reconstruction works by first detecting distinctive features in each photo, then matching these features across multiple images to find common points in the scene. Using these matches, COLMAP estimates the positions and orientations of the cameras that took the photos and reconstructs a sparse 3D point cloud representing the scene’s structure. This process is known as Structure-from-Motion (SfM).
After building the initial sparse 3D model, COLMAP can also perform Multi-View Stereo (MVS) to generate a much denser, detailed 3D reconstruction. This involves estimating depth and surface information from the photos to fill in the gaps and produce a realistic 3D surface.
In essence, COLMAP recovers detailed camera geometry at the photo capture stage. Both NeRF and Gaussian splatting require an accurate reconstruction of the scene, detailing the camera’s intrinsic (FOV, center point) and extrinsic (SE3 Poses) properties. Therefore, COLMAP makes it possible for NeRF or Gaussian Splatting to render photorealistic novel views by understanding exactly how each photo was taken.
What is Unity?
Developed over more than two decades, Unity is a popular game engine that helps people create video games and interactive experiences easily. Think of it like a powerful toolkit and workspace where game developers can build virtual worlds, characters, and gameplay without starting from scratch. Unity provides an editor environment where you can arrange objects, add colors, sounds, and behaviors—all visually and intuitively.
In Unity, everything in a game is made from “GameObjects,” which are like containers that can hold different features called “Components.” For example, a GameObject can have a model to show what it looks like, physics to make it move naturally, and scripts—programs written in the C# language—that tell it how to behave. Developers can drag and drop assets such as 3D models, textures, and sounds into their scenes to create immersive games.
Unity supports both 2D and 3D games and works on many platforms like computers, phones, and gaming consoles. It also includes tools for creating realistic lighting, animations, and physics effects. Because it’s user-friendly and powerful, Unity is widely used by indie developers and big studios alike for making games, VR experiences, simulations, and more. It speeds up game development by handling complex tasks so creators can focus on their ideas and creativity.
What is Blender?
Blender is a free, open-source software used to create 3D graphics and animations. Imagine it as a digital art studio where you can build models of anything—from characters and objects to entire worlds—using your computer. It helps artists design movies, video games, visual effects, and even 3D printed objects. Blender includes tools for sculpting shapes, adding colors and textures, creating movements, and lighting scenes realistically. Because it’s open source, anyone can use it without paying and even contribute to improving it. It’s popular for its powerful features and supportive community, making 3D design accessible to beginners and professionals alike.
While Unity focuses primarily on how a game works—its rules, behaviors, and the transitions between different states or actions—Blender is centered around crafting the visual assets that bring those games to life. Unity handles the logic and interactions, enabling developers to script gameplay, control physics, and manage how objects respond to player input or environmental factors. Meanwhile, Blender is the creative tool used to design and sculpt the detailed 3D models, textures, and animations that populate those game worlds. In essence, Blender builds the impressive visuals, and Unity gives those visuals purpose through interactive gameplay and programming. Together, they form a powerful pipeline for game development, with Blender focused on asset creation and Unity focused on game logic.
What is a C-arm imaging machine?
A C-arm imaging machine is a special X-ray device used in operating rooms to help doctors see inside the body in real time during surgeries. Named for its C-shaped arm, it connects an X-ray source on one end and a detector on the other, allowing images from various angles without moving the patient. It shows detailed, live X-ray pictures of bones, implants, and instruments, aiding surgeons in precise work, especially in orthopedic, cardiac, and emergency procedures. Its mobility and flexibility make it invaluable for guiding complex surgeries safely and accurately.
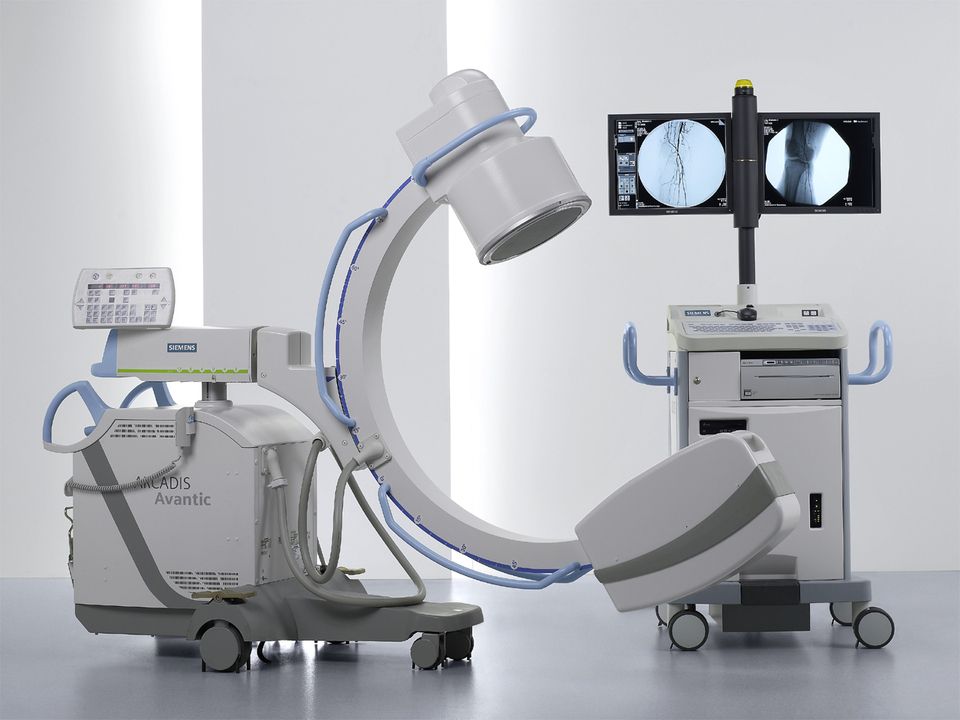
Now that we have talked about all the basic concepts and applications. Let’s dive into my toy example of building a mesh for a 2D C-arm machine using a smartphone.
Following up next is Gaussian Splatting - Toy Example