
This post follows up from my earlier post on topic modelling, analyzing scientific publications to gain knowledge on COVID-19.
Here, I want to delve into a bit deeper on how to use only relatively simple and classic natural language processing techniques to help find semantically similar documents on some subtopics of COVID-19.
Specifically, let’s try to find documents pertaining to:
Effectiveness of personal protective equipment and its usefulness to reduce risk of transmission in health care and community settings
This topic is taken out of a list of topics from COVID-19-research-challenge.
Prepare document Corpus
The preprocessing step for the texts is largely the same as before. However, I have added more tokens in the dictionary by using unigram, bigram and trigram together. This combination is helpful for taking phrases such as “crystal structure” into account.
data_raw = load_data() # raw data from Kaggle
data_list = pickle.load( open( "data_list.p", "rb" ) ) # with preprocessing done already
# Build the bigram models
bigram = gensim.models.phrases.Phrases(data_list['title'], min_count=20, threshold=10)
# Build the trigram models
trigram = gensim.models.phrases.Phrases(bigram[data_list['title']], threshold=10)
breakdown = trigram[data_list['title']]
# Count n-gram frequencies
frequency = defaultdict(int)
for text in breakdown:
for token in text:
frequency[token] += 1
processed_corpus = [[token for token in text if frequency[token] > 60] for text in data_list['abstract']]
Some token examples:
unigram_examples[0:10]
Out[11]:
['sequence',
'rna',
'transfer',
'synthesis',
'murine',
'coronavirus',
'receptor',
'family',
'novel',
'protein']
bigram_examples[0:10]
Out[12]:
['crystal_structure',
'hepatitis_virus',
'rt_pcr',
'severe_acute',
'respiratory_syndrome',
'sars_cov',
'rna_synthesis',
'vaccinia_virus',
'sars_coronavirus',
'intensive_care']
trigram_examples[0:10]
Out[16]:
['ucc_uuu_cgu',
'002_05_2015',
'x_xxy_yyz',
'x_xxz_zzn',
'run_tiled_primers',
'g_guu_uuu',
'dme1_chrx_2630566',
'ssc_circ_009380',
'vb_bbrs_phb09',
'vb_bbrm_phb04']
Query
I create a dictionary, convert the documents to a bag-of-word vectors, construct a term-frequency-inverse-document-frequency matrix, and calculate the similarity of the corpus based on cosine distance.
############ Gensim
dictionary = corpora.Dictionary(processed_corpus)
print(dictionary)
bow_corpus = [dictionary.doc2bow(text) for text in processed_corpus]
# train the model
tfidf = models.TfidfModel(bow_corpus)
corpus_tfidf = tfidf[bow_corpus]
index = similarities.MatrixSimilarity(corpus_tfidf)
Once I have the similarity matrix of the entire corpus, I can start to compare the query against each one of them.
def parse(string, length=25):
if isinstance(string, str):
token, *vec = string.split(' ')
vec = map(float, vec)
return token, vec
else:
print (string)
return None
def flatten_list(x):
return [ item for sublist in x for item in sublist]
def preprocess_query(words, stopwords, wnl, dictionary):
words = words.split(' ')
words = [token.lower() for token in words]
words = [token for token in words if token not in stopwords.words('english')]
words = [wnl.lemmatize(token) for token in words]
query_vec = dictionary.doc2bow(words)
return query_vec
def search(index, tfidf, word, stopwords, wnl, dictionary, data_raw, total_doc_samples):
query_vec = preprocess_query(word, stopwords, wnl, dictionary)
sims = index[tfidf[query_vec]]
# keep track of how similar each document is to the query
rank = {i:value for i, value in enumerate(sims)}
sorted_rank = sorted(rank.items(), key=lambda x:x[1])
results = []
for i in range(1,total_doc_samples+1):
string = data_raw['title'][sorted_rank[-i][0]]
results.append((sorted_rank[-i], string))
return results
Search results
I rank all the documents in the order of decreasing similarity and pick only the top 1000 most similar documents.
from nltk.corpus import stopwords
import nltk
wnl = nltk.WordNetLemmatizer()
words = 'Effectiveness of personal protective equipment and its usefulness to reduce risk of transmission in health care and community settings'
total_doc_samples = 1000
results = search(index, tfidf, words, stopwords, wnl, dictionary, data_raw, total_doc_samples)
x = np.zeros((len(results), len(dictionary)), dtype=np.float16)
sim_x = np.zeros((len(results),), dtype=np.float16)
sim_doc_titles = []
for i, result in enumerate(results):
index = result[0][0]
doc = corpus_tfidf[index]
col = [item[0] for item in doc]
v = [item[1] for item in doc]
x[i, col] = v
sim_x[i] = result[0][1]
sim_doc_titles.append(result[1])
Since a dry list of documents may be boring to look at, I cluster the search results and put them in a tree. Sklearn provides a very handy script which I adopt for this subtask.
from sklearn.cluster import AgglomerativeClustering
model = AgglomerativeClustering(affinity='cosine',
distance_threshold=0, n_clusters=None,
linkage='complete')
model = model.fit(x)
from scipy.cluster.hierarchy import dendrogram
def plot_dendrogram(model, **kwargs):
# Create linkage matrix and then plot the dendrogram
# create the counts of samples under each node
counts = np.zeros(model.children_.shape[0])
n_samples = len(model.labels_)
for i, merge in enumerate(model.children_):
current_count = 0
for child_idx in merge:
if child_idx < n_samples:
current_count += 1 # leaf node
else:
current_count += counts[child_idx - n_samples]
counts[i] = current_count
linkage_matrix = np.column_stack([model.children_, model.distances_,
counts]).astype(float)
# Plot the corresponding dendrogram
dendrogram(linkage_matrix, **kwargs)
plt.title('Hierarchical Clustering Dendrogram')
# plot the top three levels of the dendrogram
plot_dendrogram(model, truncate_mode='level', p=4)
plt.xlabel("Number of points in node (or index of point if no parenthesis).")
plt.ylabel("distances")
plt.savefig(os.path.join(output_dir, 'dendrogram_similar_docs.png'), transparent=True , dpi=400, bbox_inches='tight')
plt.show()
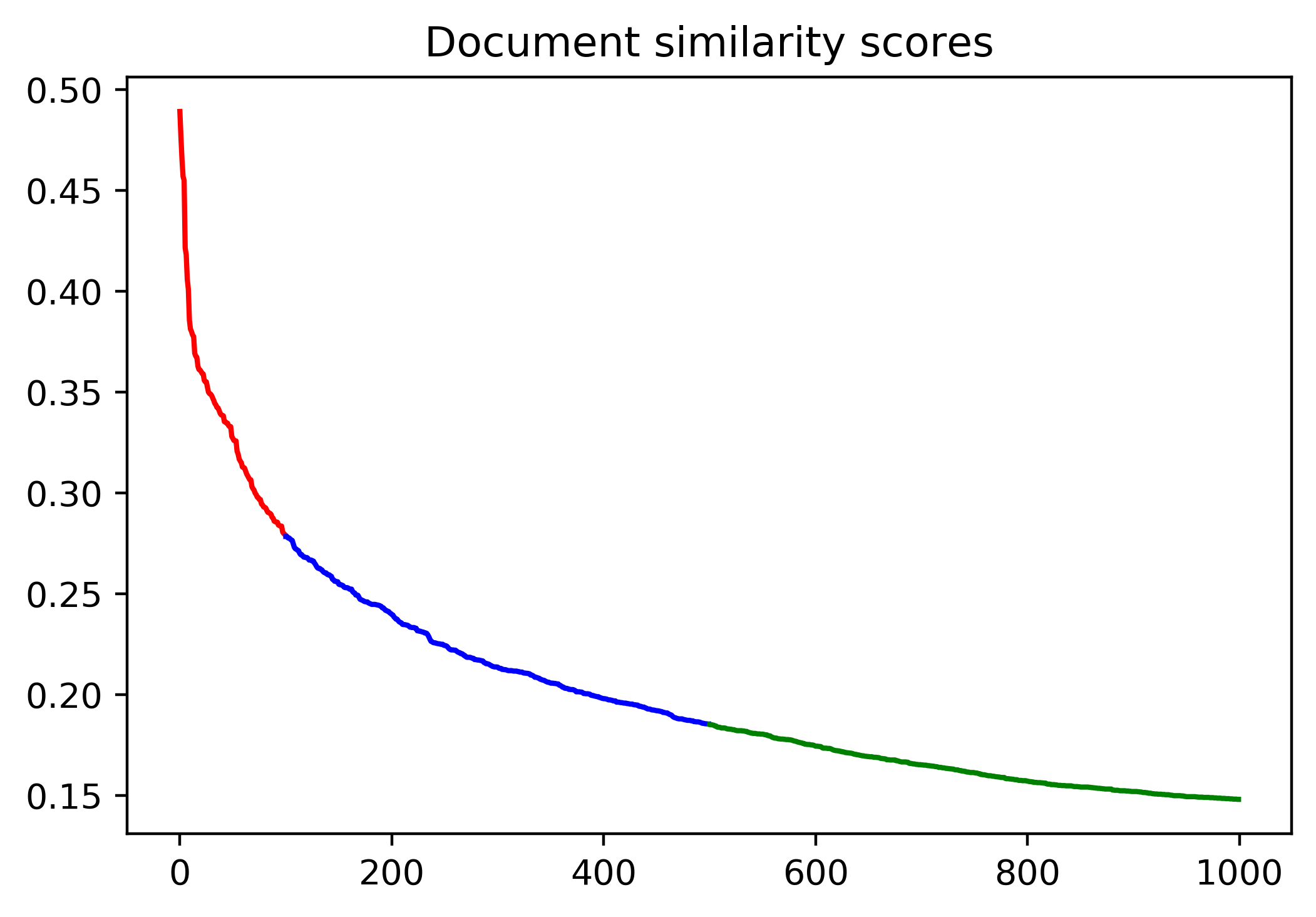
The similarity of documents decays gradually and there aren’t that many semantically similar documents to the query have been found. I group highly similar documents in red, moderately similar documents in blue, and not-quite similar documents in green.
I personally would say only those in red are relatively relevant and are therefore worth reading the full content of the articles. Here are the list of some of the titles in each color group.
- Effectiveness of handwashing in preventing SARS: a review
- Response and role of palliative care during the COVID-19 pandemic: a national telephone survey of hospices in Italy
- Disinfection efficiency of positive pressure respiratory protective hood using fumigation sterilization cabinet
- Rapid De-Escalation and Triaging Patients in Community-Based Palliative Care
- Face shields for infection control: A review
- Helmet Modification to PPE with 3D Printing During the COVID-19 Pandemic at Duke University Medical Center: A Novel Technique
- Personal Protective Equipment
- Brief guideline for the prevention of COVID-19 infection in head and neck and otolaryngology surgeons
- Taking the right measures to control COVID-19
- Outbreaks in Health Care Settings
- The Role of Managerial Epidemiology in Infection Prevention and Control
- Elective surgery in the time of COVID-19
- Evaluation of the Person Under Investigation
- Appraisal of recommended respiratory infection control practices in primary care and emergency department settings
- Methicillin-resistant Staphylococcus aureus, Clostridium difficile, and extended-spectrum β-lactamase–producing Escherichia coli in the community: Assessing the problem and controlling the spread
- Variation in health care worker removal of personal protective equipment
- How Should U.S. Hospitals Prepare for Coronavirus Disease 2019 (COVID-19)?
- Head and neck oncology during the COVID-19 pandemic: Reconsidering traditional treatment paradigms in light of new surgical and other multilevel risks
- Modeling layered non-pharmaceutical interventions against SARS-CoV-2 in the United States with Corvid
- Protecting health care workers from SARS and other respiratory pathogens: A review of the infection control literature
- Covid-19: What’s the current advice for UK doctors?
- Cost-effectiveness analysis of N95 respirators and medical masks to protect healthcare workers in China from respiratory infections
- Assessment of Temporary Community-Based Health Care Facilities During Arbaeenia Mass Gathering at Karbala, Iraq: Cross-Sectional Survey Study
- 23 Response to SARS as a prototype for bioterrorism Lessons in a Regional Hospital in Hong Kong
- Recommendations and guidance for providing pharmaceutical care services during COVID-19 pandemic: A China perspective
- Could influenza transmission be reduced by restricting mass gatherings? Towards an evidence-based policy framework
- Equipment for Exotic Mammal and Reptile Diagnostics and Surgery
- Infrastructure and Organization of Adult Intensive Care Units in Resource-Limited Settings
- Risk factors for febrile respiratory illness and mono-viral infections in a semi-closed military environment: a case-control study
- Contamination during doffing of personal protective equipment by healthcare providers
- Facing the threat of influenza pandemic - roles of and implications to general practitioners
- Supplies and equipment for pediatric emergency mass critical care
- SARS Transmission among Hospital Workers in Hong Kong
- The Demand for Health Care
- Isolation Facilities for Highly Infectious Diseases in Europe – A Cross-Sectional Analysis in 16 Countries
- A systematic risk-based strategy to select personal protective equipment for infectious diseases
- 4 Steps in the selection of protective clothing materials
- Helen Salisbury: Is general practice prepared for a pandemic?
- Performance of materials used for biological personal protective equipment against blood splash penetration
- Role of viral bioaerosols in nosocomial infections and measures for prevention and control
- Guideline for Antibiotic Use in Adults with Community-acquired Pneumonia
- Hydroxychloroquine (HCQ): an observational cohort study in primary and secondary prevention of pneumonia in an at-risk population
- On the 2-Row Rule for Infectious Disease Transmission on Aircraft
- The outbreak of COVID-19: An overview
- Hendra virus in Queensland, Australia, during the winter of 2011: Veterinarians on the path to better management strategies
- Visibility and transmission: complexities around promoting hand hygiene in young children – a qualitative study
- Mapping road network communities for guiding disease surveillance and control strategies
- A COVID-19 Risk Assessment for the US Labor Force
- Gut microbiome and the risk factors in central nervous system autoimmunity
- Public health and medical care for the world's factory: China's Pearl River Delta Region
- Global health goals: lessons from the worldwide effort to eradicate poliomyelitis
- Population response to the risk of vector-borne diseases: lessons learned from socio-behavioural research during large-scale outbreaks
- Reduced Risk of Importing Ebola Virus Disease because of Travel Restrictions in 2014: A Retrospective Epidemiological Modeling Study
- Investigation of three clusters of COVID-19 in Singapore: implications for surveillance and response measures
- The Perceived Threat of SARS and its Impact on Precautionary Actions and Adverse Consequences: A Qualitative Study Among Chinese Communities in the United Kingdom and the Netherlands
- Association of COVID-19 Infections in San Francisco in Early March 2020 with Travel to New York and Europe
- Harnessing the privatisation of China's fragmented health-care delivery
- Toward a consensus view in the management of acute facial injuries during the Covid-19 pandemic
- Selected nonvaccine interventions to prevent infectious acute respiratory disease
- Prevalence of Psychiatric Disorders Among Toronto Hospital Workers One to Two Years After the SARS Outbreak