
Dear readers,
This is my introductory course on some basic concepts on database, searches, and optimization. MongoDB is a NoSQL database that stores data in flexible, JSON-like documents, rather than the traditional table-based relational database structure. This allows for more dynamic schemas, where fields can vary between documents, and data can be nested in complex hierarchies. ###Key Features of MongoDB:
- Document-Oriented Storage: MongoDB stores data in BSON (binary JSON) format, which means data can be represented in a rich, hierarchical structure. This makes it more adaptable to changing data models.
What is a data model?
Conceptual data models
These model types provide a high-level, conceptual view of your data. They identify key entities—like customers, products, orders, and payments—and show how these entities relate to each other. This model is designed to help business stakeholders understand how different parts of the data interact without diving into technical details.
- Example: For a retail company, a conceptual data model might include categories like customers, products, orders, and payments. The relationships between these categories would be mapped out visually to help stakeholders see how the data from different parts of the business interact without getting into specifics like data types or storage methods.
Logical data models
Logical data models build on the conceptual model by adding more detail. They define the data elements, their attributes, and the relationships between them in a way that aligns more closely with how the data will be implemented in a database. This model bridges the gap between business needs and technical design, making it easier for IT teams to plan the database structure.
- Example: Continuing with the retail company example, a logical data model would define specific attributes for each category defined in the conceptual model. For instance, the customer category might include attributes like customer ID, name, email, and address. The order category could include details like order ID, order date, customer ID, and total amount. This additional detail translates business concepts into a structured database design, though it doesn’t yet address the physical aspects.
Physical data models (Electronic)
Physical data models provide the most detail. They take the logical model and turn it into a specific framework for storing and managing the data within a particular database system. This includes defining the structure of tables, the types of data that will be stored in each column, and how the data will be indexed and accessed. The physical model optimizes the database for performance and maintains accurate data relationships.
- Example: For our hypothetical retail company, the physical data model would translate the logical model into a concrete database design. The customer category might become a table named “Customers,” with fields for customer information like ID, name, email, and address. Similarly, the order category would be “Orders,” containing details like order date, customer ID, and total amount. The physical model also defines how these tables interact within the database to ensure efficient data retrieval and integrity.
- Scalability: MongoDB is designed to scale horizontally, which means you can distribute data across multiple servers. This is especially useful for handling large volumes of data and high traffic loads.
- Flexibility: Unlike traditional relational databases that require a predefined schema, MongoDB allows for flexible schemas (mixture of different data variable types, inconsistent number of fields, etc), making it easier to handle data that doesn’t fit neatly into a predefined structure.
- High Performance: MongoDB is optimized for read and write performance, and it supports indexing and querying that can improve data access speeds.
- Distributed Database: MongoDB is built for distributed systems, with features like replication, sharding (splitting a large database into smaller partitions and storing them in various locations), and automatic failover, making it highly resilient and available.
- Aggregation Framework: MongoDB provides a powerful aggregation framework that allows for complex data processing and transformation directly within the database.
- Integration with Modern Development Stacks: MongoDB integrates well with many modern development environments, including JavaScript, Python, and Node.js, making it popular among developers building web applications.
###Why MongoDB is Popular:
- Ease of Use: MongoDB’s flexible document model is more aligned with how developers think about data, especially in web and mobile applications. This makes it easier to use and faster to develop with compared to traditional relational databases.
- Scalability: As data grows, MongoDB’s ability to scale horizontally by adding more servers allows businesses to manage large datasets without significant performance degradation.
- Flexible Schema: The ability to store various data types and structures in the same collection without needing to define a strict schema upfront makes MongoDB ideal for rapidly evolving applications.
- Strong Community and Ecosystem: MongoDB has a large and active community, extensive documentation, and a wide range of tools and integrations, making it a popular choice for developers and companies.
- Cloud-Native: MongoDB Atlas, the cloud version of MongoDB, offers a managed service that abstracts away the complexities of database management, making it easier for developers to deploy and scale databases in the cloud.
-
Support for Big Data and Real-Time Applications: MongoDB’s performance characteristics and scalability make it well-suited for big data applications, real-time analytics, and other modern use cases where traditional databases may struggle. MongoDB’s combination of flexibility, performance, and scalability has made it one of the most popular NoSQL databases, especially in environments where developers need to move quickly and handle large, complex datasets.
- I have read through its documentation and tutorials on MongoDB website (https://www.mongodb.com/). They are well-suited for beginners like myself and offer MongoDB University courses for free.
Some basic differences between MongoDB (NoSQL) vs SQL database
SQL is very fast for lookup, and for adding new rows, which makes it very suitable for a situation where we need to often add and remove new samples. However, its schema is rigid. In other words, its columns are preset, so adding or removing a field can be tricky. Also, its schema can only handle single variable type within a field, which means it can be less flexible.
On the other hand, MongoDB lets us mix multiple variable types in the same field or add or remove new columns, with each entry can have different number of fields. Apart from the standard integer, string, double, MongoDB uses unique variable types. For example, ID Key, ISODATE, etc. Each sample is a document. Many related or similar documents grouped together are called a collection. Many related or similar collections grouped together are called a database and putting several databases together are called a cluster. It can scale easily. Despite its flexibility, MongoDB can enforce constraints on its schema and validate its documents against its constraints.
How MongoDB handles relationships?
In MongoDB, we have 3 different ways to combine a key (unique) to a value (information). The first way is one-to-one. This is most useful when we need to look up a unique record. Say we identify this particular record with its own unique id that is automatically generated when we insert it into a database. The second way is one-to-many. This is most useful when we have multiply items inside an array for a field. We can search through them. For example, a single record possesses multiple tags or labels. The last way is many-to-many. It is very paramount that we understand the purpose and the functional requirements of database. The four functional pillars of a good database are atomicity, consistency, isolation and durability.
- Atomicity = All operations will either succeed or fail together.
- Consistency = All changes made by operations are consistent with database constraints or meet the schema validation rules.
- Isolation = Multiple transactions can happen at the same time without affecting the outcome of other transaction.
- Durability = All of the changes that are made by operations in a transaction will persist, no matter what.
Why do we use indexing?
Indexing in MongoDB is a powerful feature that enhances the efficiency of query operations by allowing the database to quickly locate and access the data needed without scanning the entire collection. This can significantly improve query performance, especially in large datasets.
Benefits of Indexing in MongoDB:
- Improved Query Performance: Indexes allow MongoDB to search for records more quickly by narrowing down the search space. Instead of scanning the entire collection, the database can directly access the indexed fields, resulting in faster query execution.
- Reduced Resource Consumption: Efficient indexing reduces the CPU and memory load on the database server by minimizing the amount of data that needs to be processed during queries.
- Enhanced Sorting: Indexes can also improve the performance of sort operations. If a query requests data in a sorted order based on an indexed field, MongoDB can retrieve the data in the desired order without additional sorting, saving time and resources.
- Faster Data Aggregation: Indexes can accelerate the performance of aggregation operations that involve filtering or sorting, allowing for quicker insights and data analysis.
- Support for Unique Constraints: MongoDB indexes can enforce unique constraints, ensuring that a particular field or combination of fields in a collection is unique across all documents. This is useful for maintaining data integrity, such as ensuring unique email addresses in a user collection.
- Geospatial Queries: MongoDB supports geospatial indexes, enabling efficient querying of location-based data. This is beneficial for applications that involve mapping, geolocation services, or any feature requiring spatial data processing.
- Text Search Optimization: MongoDB offers text indexes that optimize the performance of text search queries, allowing for efficient full-text search within documents.
How Indexing is Done in MongoDB:
Creating and managing indexes in MongoDB is straightforward. Here’s how you can do it:
- Single Field Index: The simplest form of an index is a single field index, which is created on a specific field in a collection. This is useful for queries that frequently filter or sort based on this field.
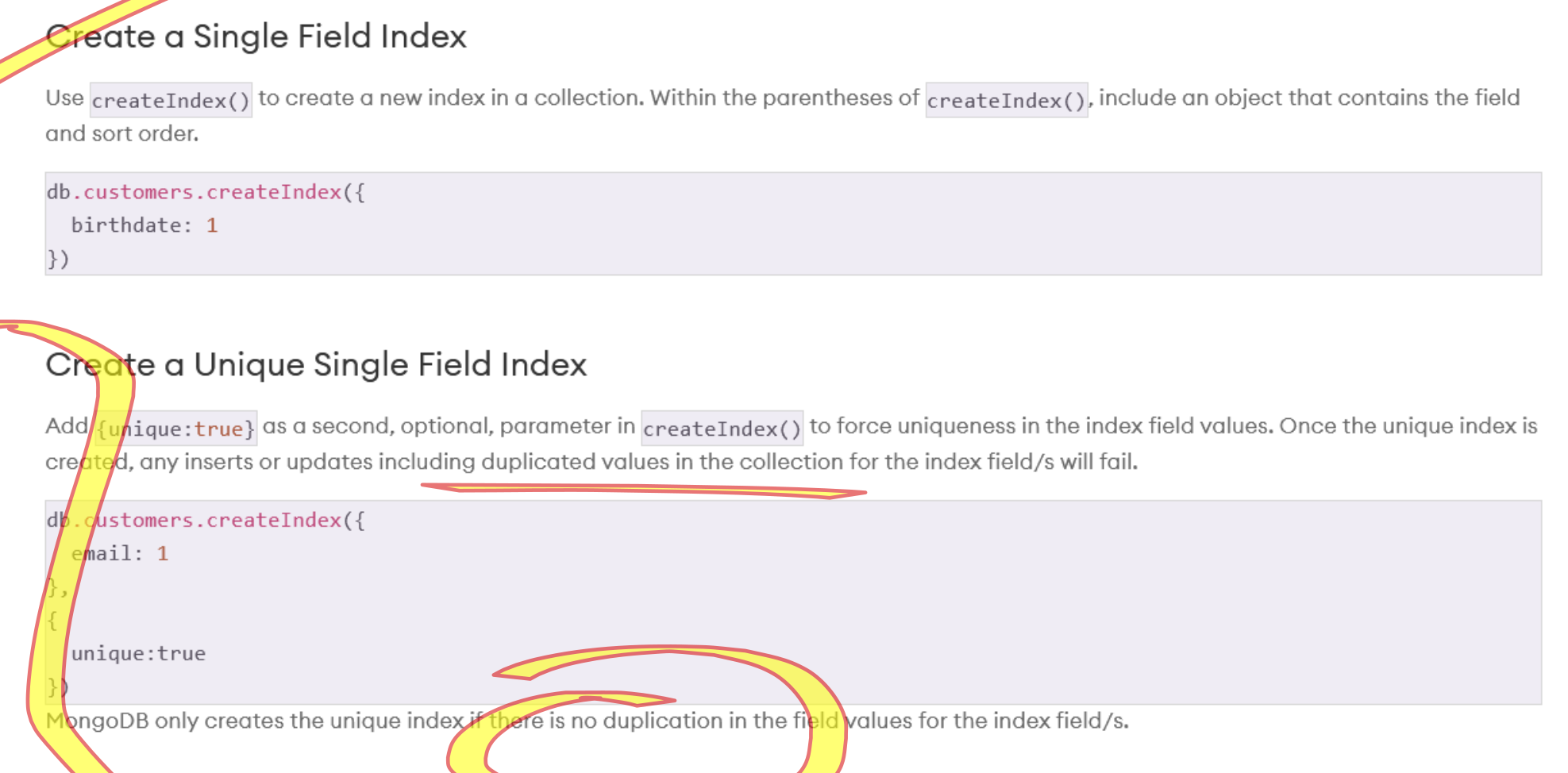
1 specifies ascending order, while -1 would specify descending order.
When we query a database, instead of searching through all its documents, we can just search through this index. This saves time by searching in fewer places. However, if we have creates too many different indices, we may lose out especially we need to update them as well whenever we updates the underlying documents. Each update requires a write operation on the index too.
So, we may want to let an index expire on its own after some time.
TTL Index: A Time-To-Live (TTL) index can automatically remove documents from a collection after a certain period. db.collection.createIndex({ createdAt: 1 }, { expireAfterSeconds: 3600 })
-
Trick 1: create index that can be used to speed up the search. We create an index based on frequently observed queries on some of the fields. Then when we query, if its corresponding index exists, the search will automatically use it.
-
Trick 2: indexing order matters. A rule of thumb is that we filter or use Boolean selection to reduce the number of documents or results as early as feasible. Then we perform more complicated / expensive operations, such as sorting.
Index management
* How to examine what indices built in the database so far?
* What happen if we are searching on the fields that have no index?
* How to remove redundant index?
Let’s take a look with the explain method that delineates how MongoDB performs searches. Without an index is not going to stymie the search progress. MongoDB has different mode for finding the subset of documents that match the queries.
COLLSCAN: collection scan is performed, without accessing the index
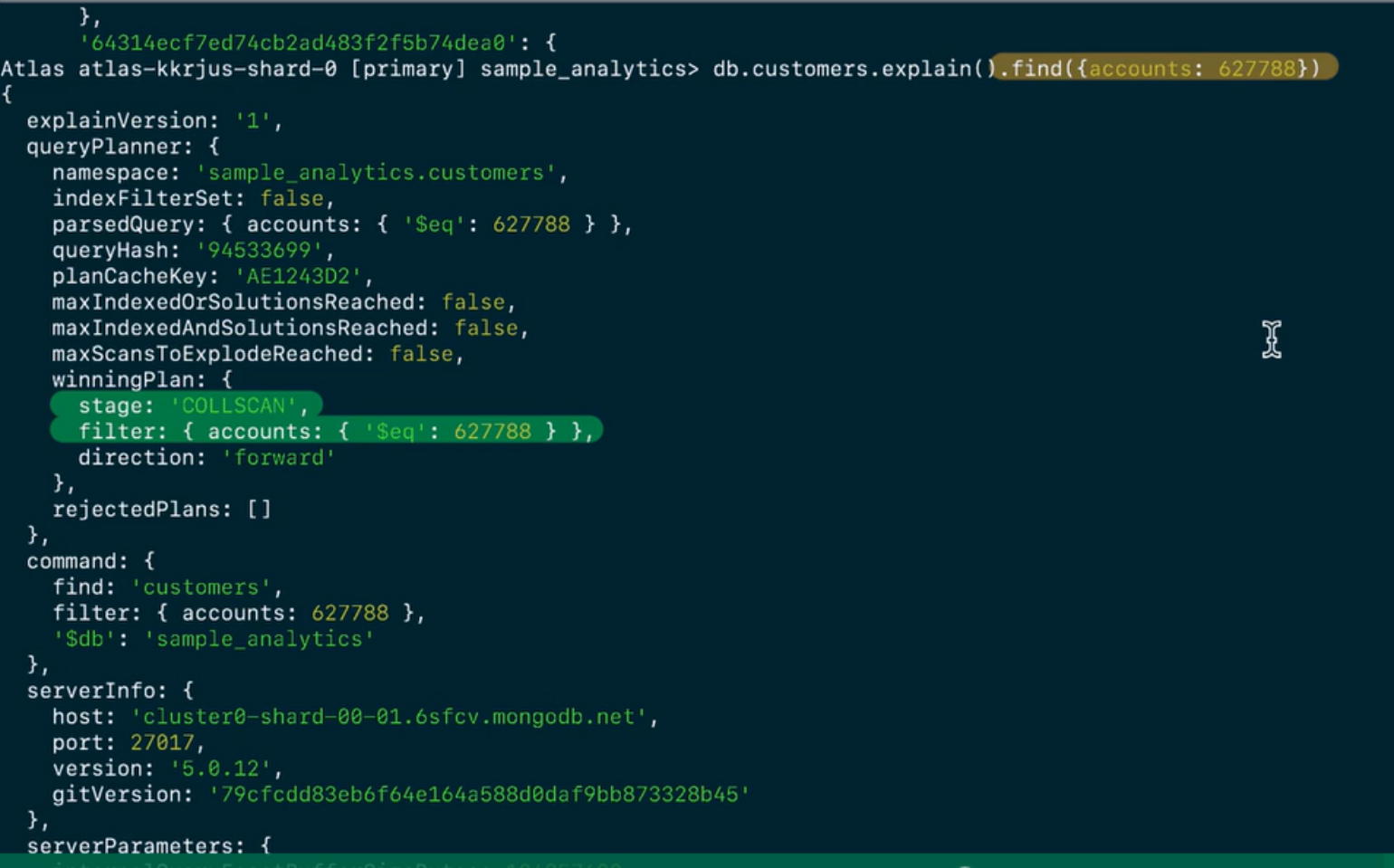
IXSCAN: indicate whether query uses index or not FETCH: read the documents SORT: sort the search results in memory
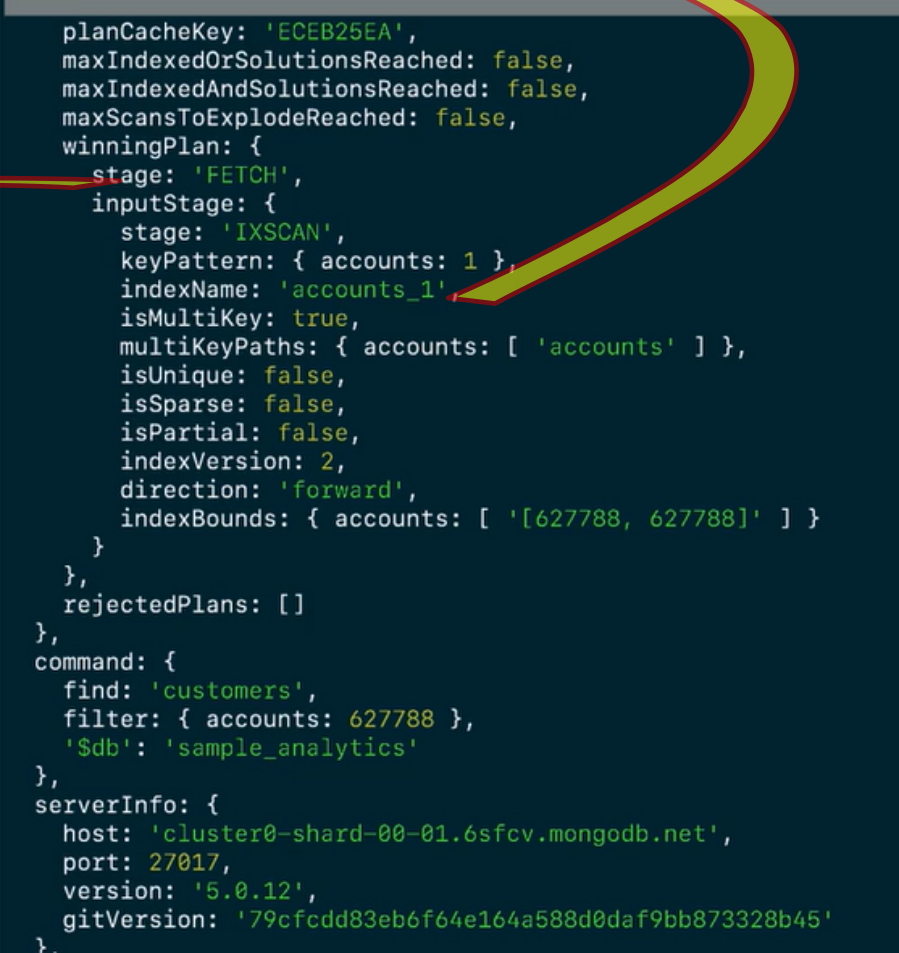
- Trick: when we are only after some specific fields, we can use projection to display only the relevant fields and hide others.

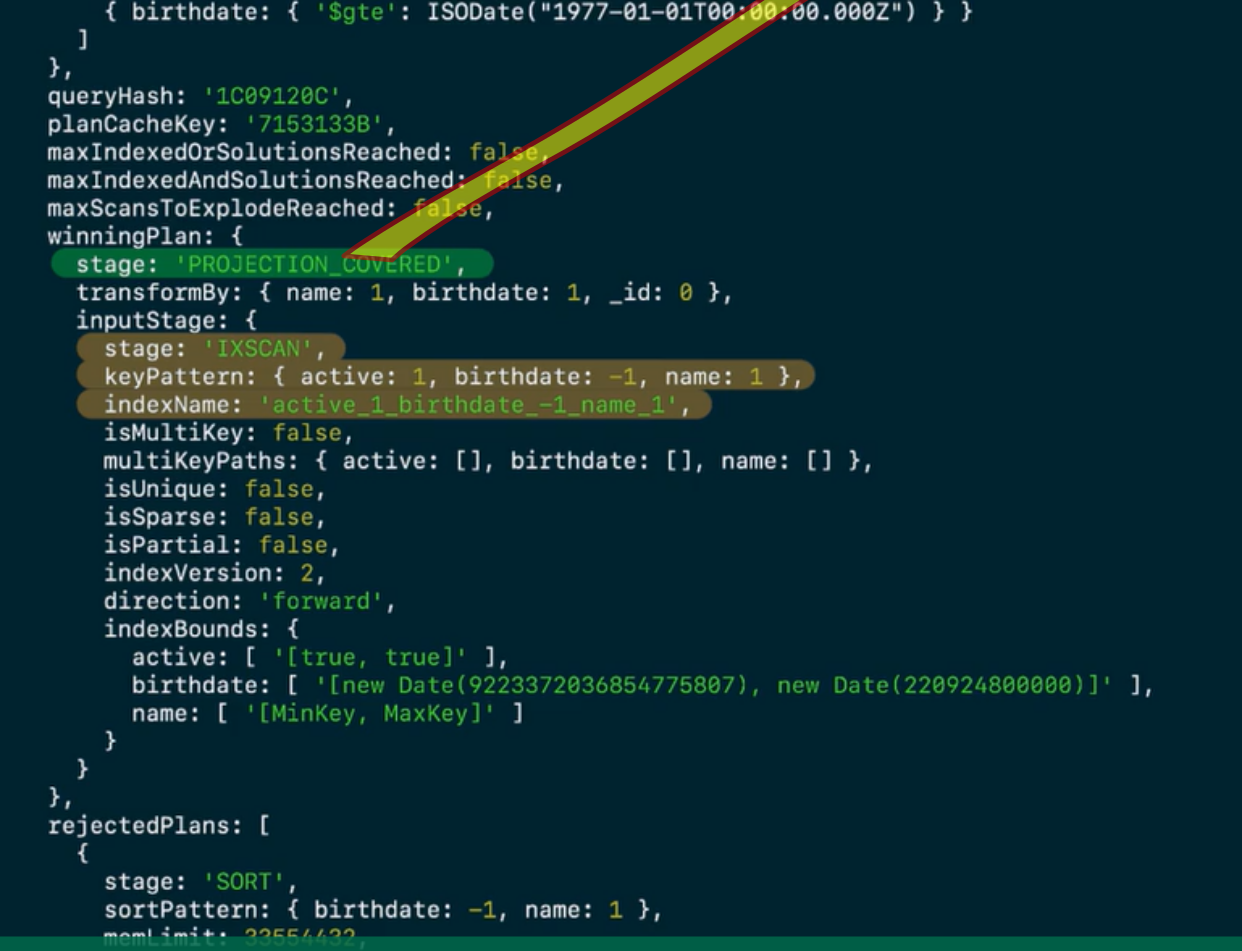
Furthermore, we can turn a single field index into multiple fields index (aka compound index) to make searching more than one field more efficient. However, the order of the items in the field matters to the efficiency, but not search results.
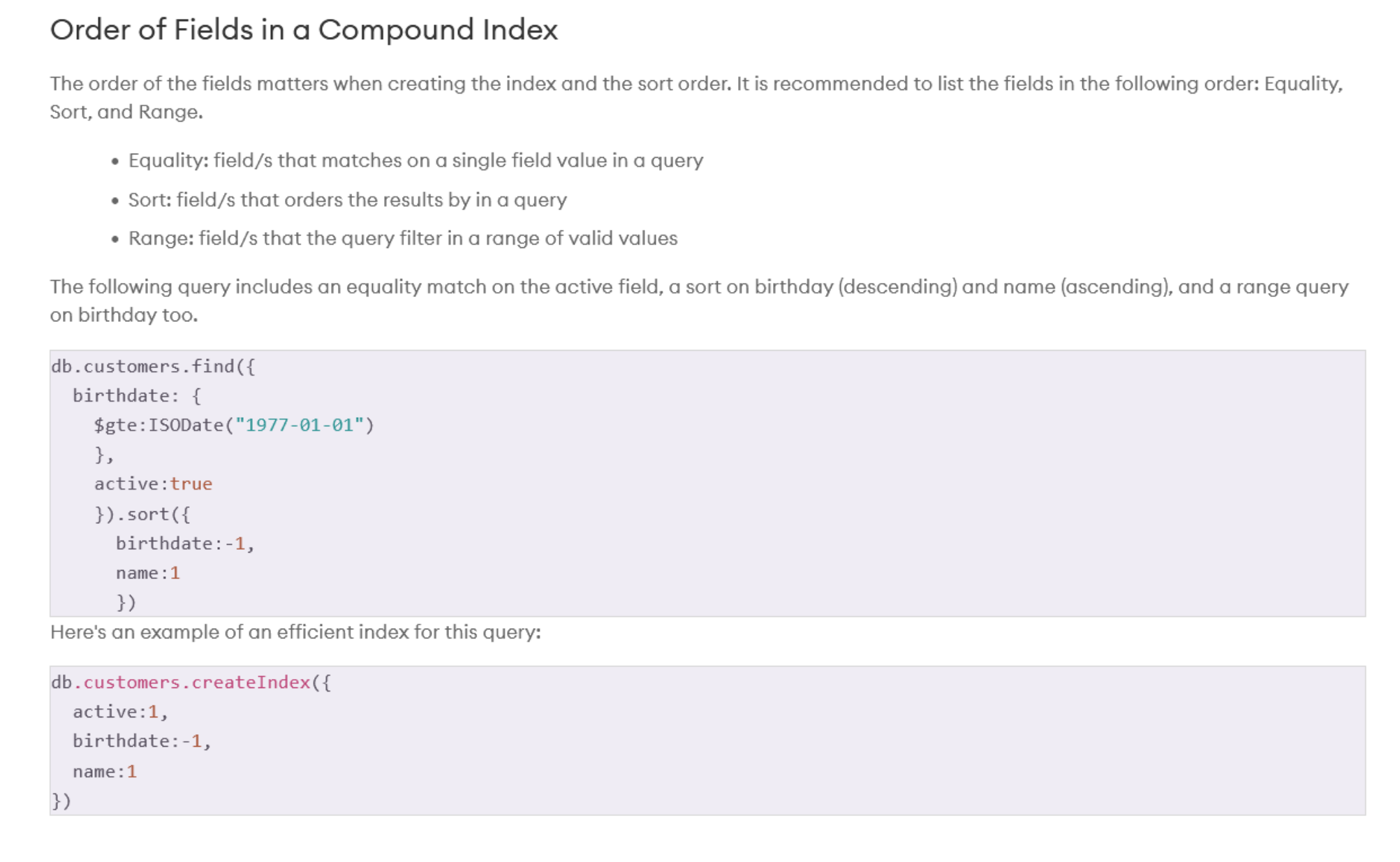
This MongoDB tutorial does not recommend users to delete indices when they become obsolete. This is because we often can delete the index that we still need. Instead of deleting it, we can just hide the index from use and check to see if anything else breaks as a result.
Delete = dropIndex hide index = hideIndex
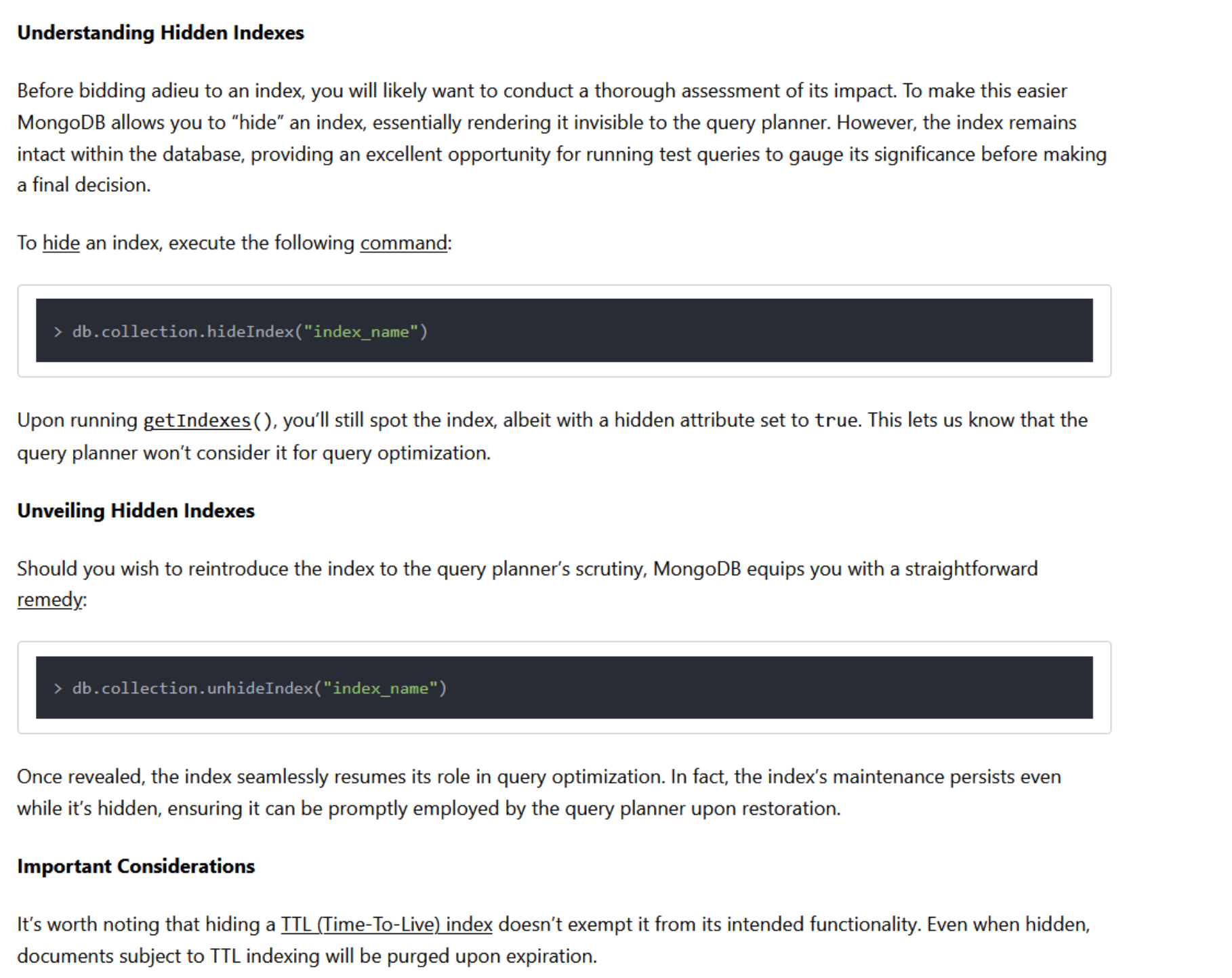

Commonly Used APIs
We can use different filters . The chose of filters depend on the data type of the field that we are looking at.
If it is just a plain and simple string, integer, float, double, etc, we can use pretty much anything.
Logical operators
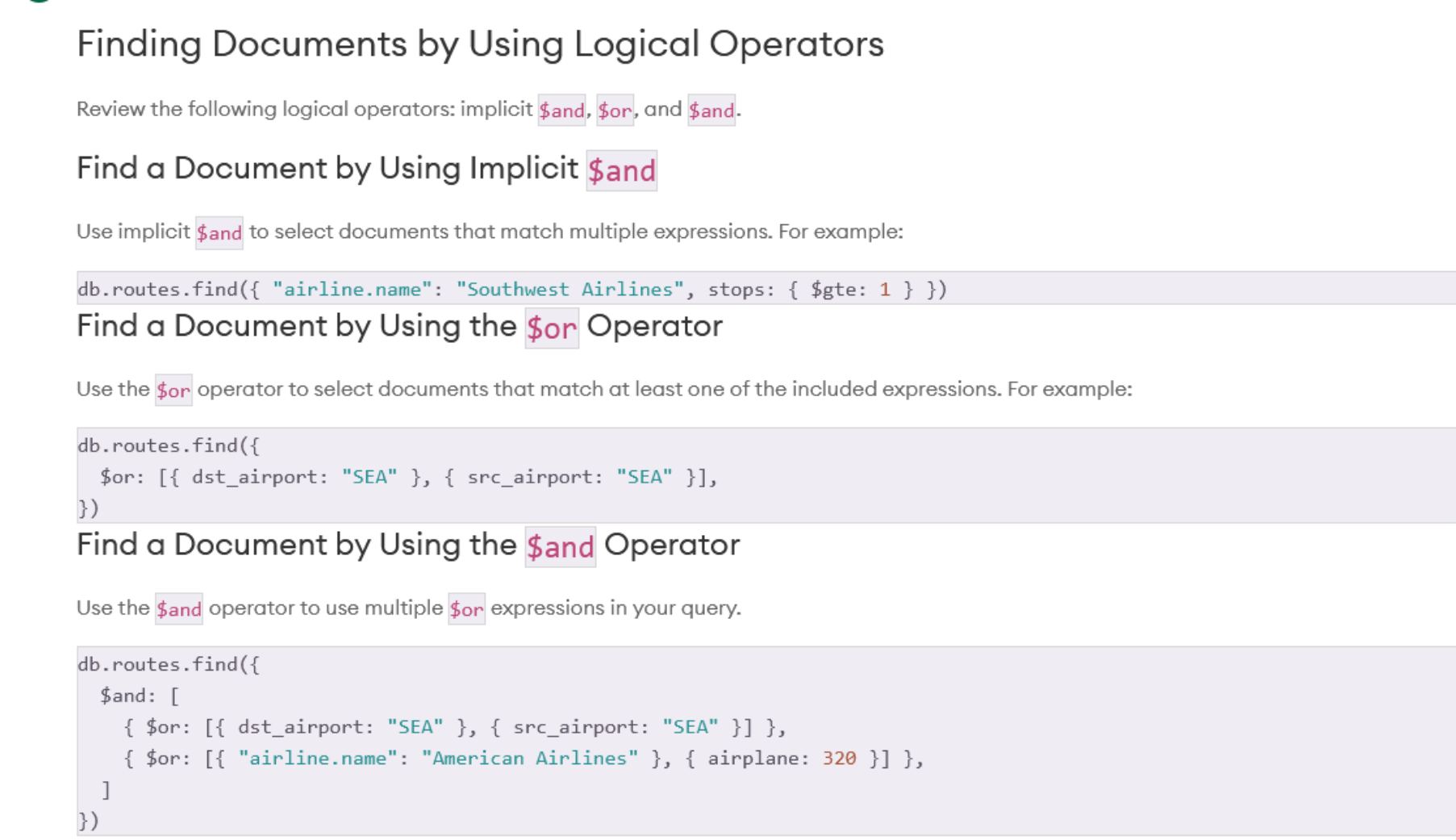
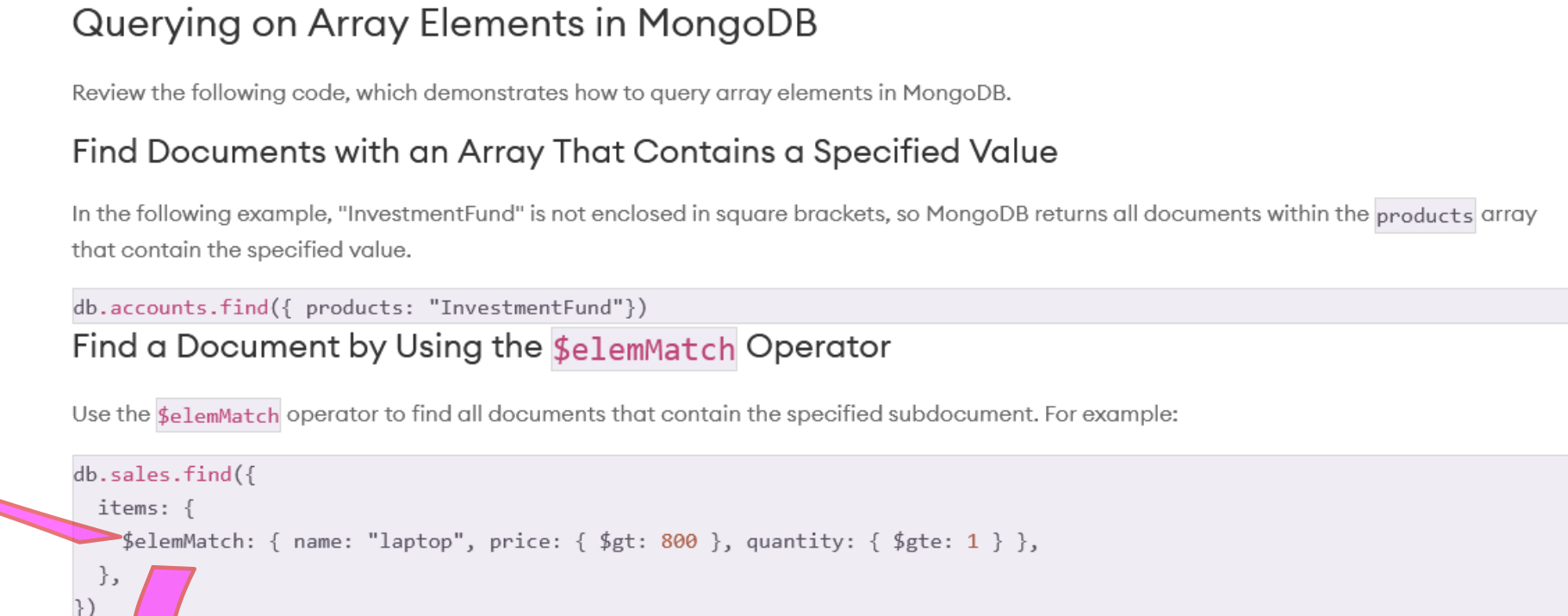
Some field contain arrays. Arrays are data structure that inside itself, contains data or elements. If we want to search inside an array, we need to do this.
We use the operator called elemMatch that looks up multiple fields and across every elements / all elements.
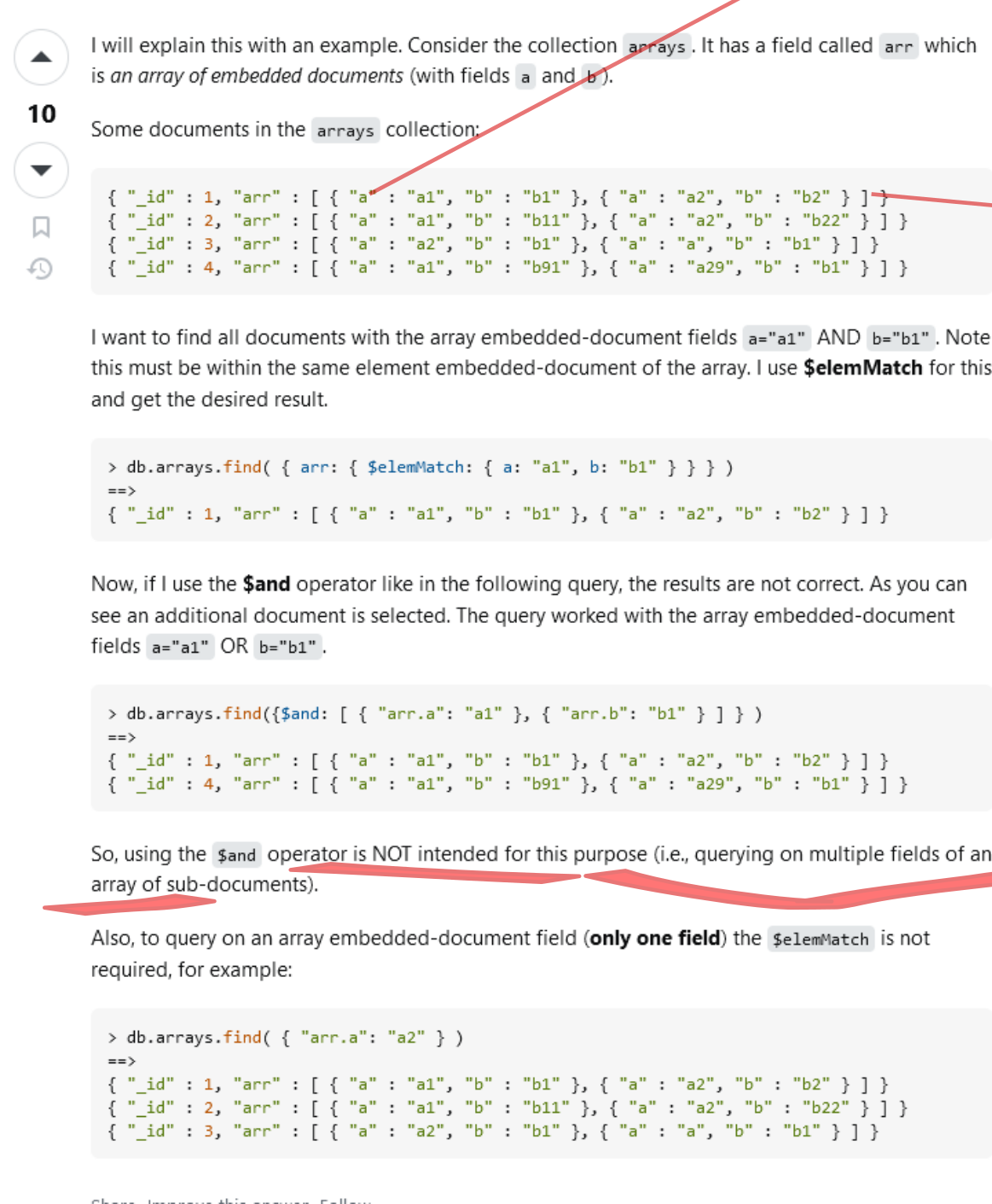
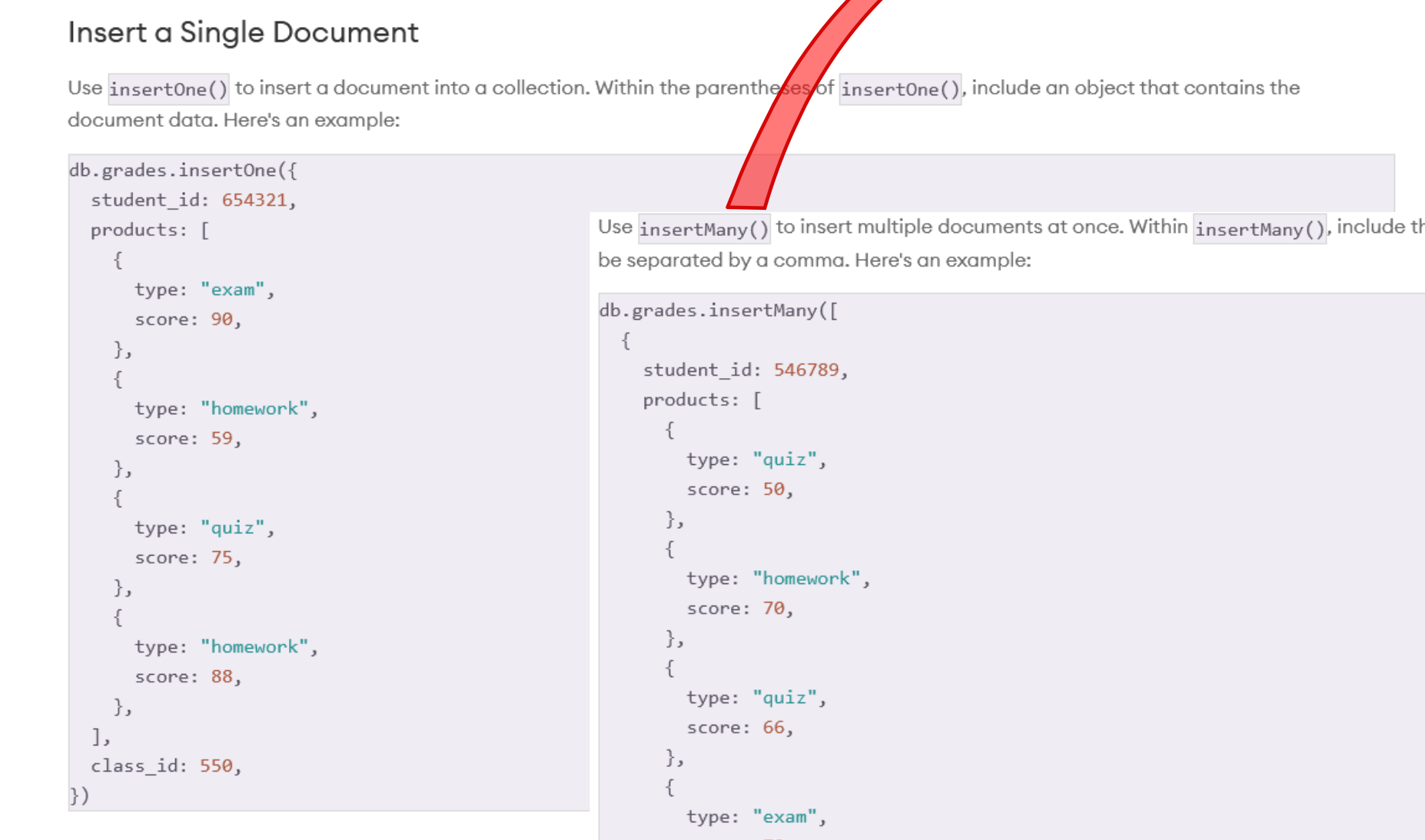
Many belongs to the family of bulk-write-method. It accesses multiple documents at once, with the benefit of reducing the number of round trips to the server and improved efficiency.
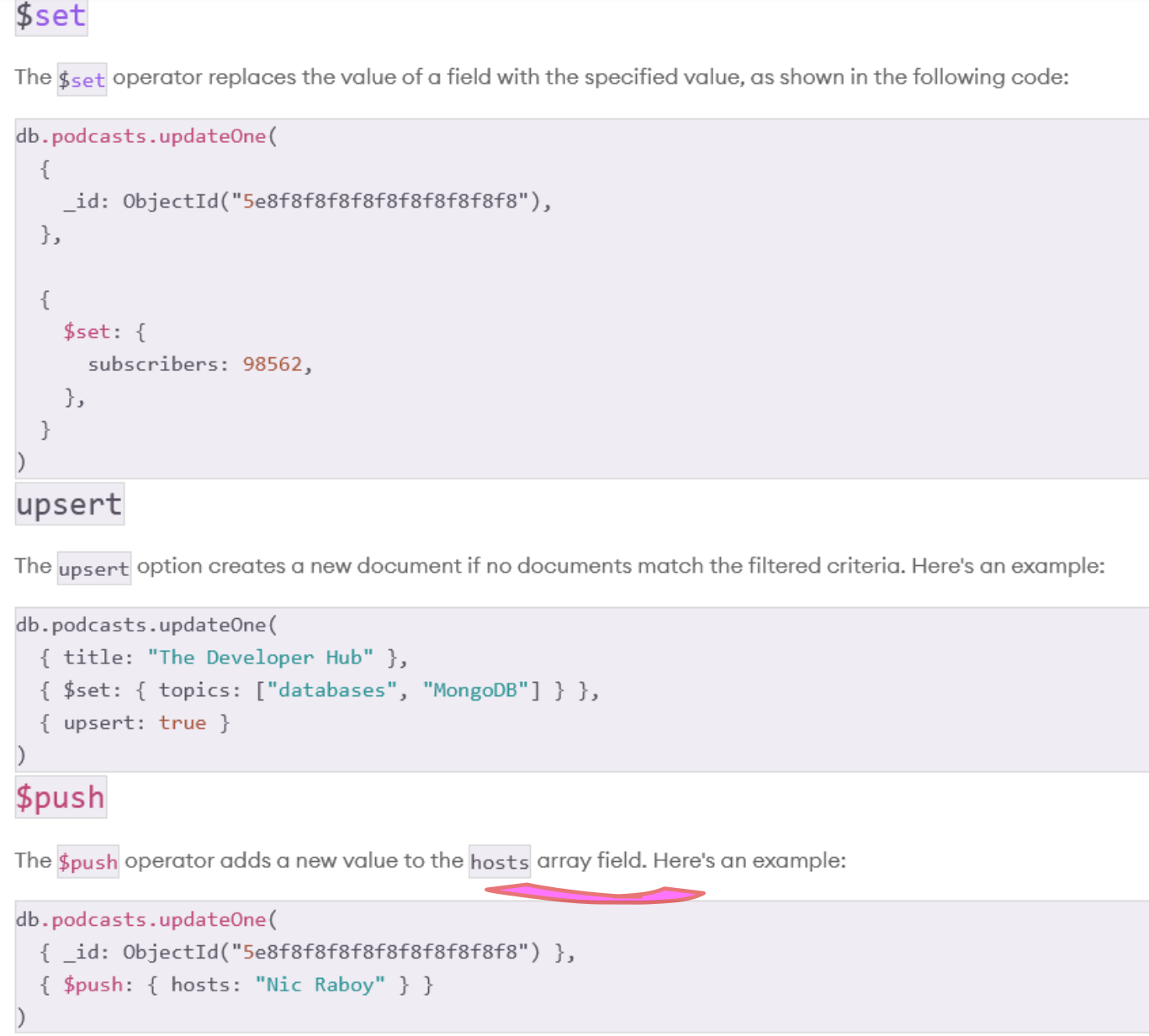

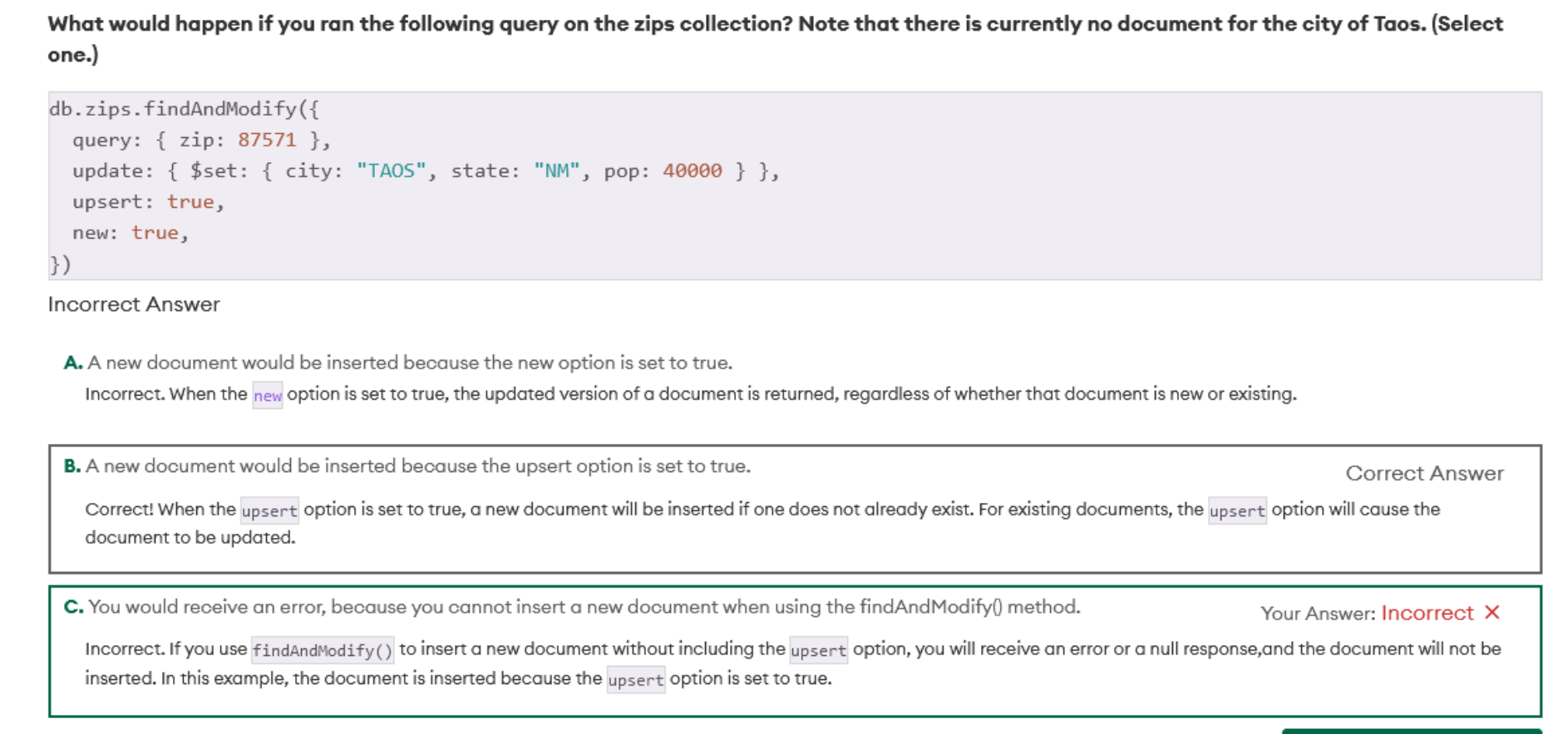
If we cannot find a document, we can create it with the desired fields by turning the upsert=True
Array is a special data structure, so we use push to append a new element to the array of existing elements.
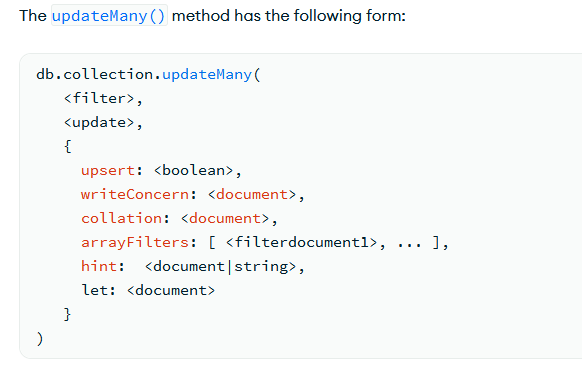

we can also use findAndModify to perform an update operation. This is helpful for keep track of statistics such as counts.

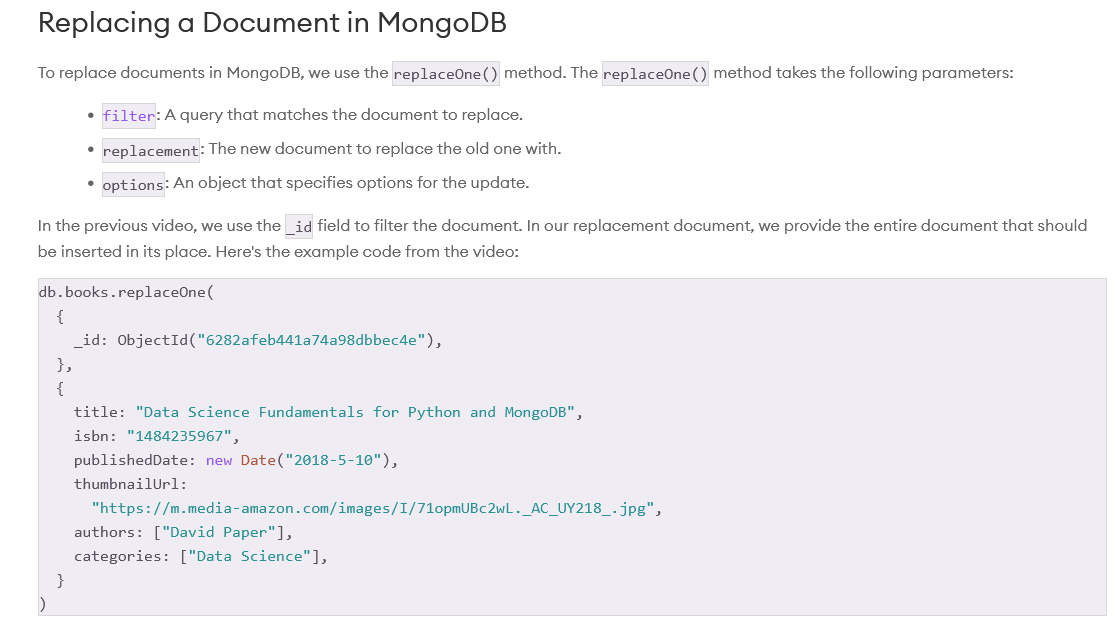
NOTE: when input to the APIs is null / empty, the functions perform like we are working on all documents. CountDocuments counts all documents. DeleteMany deletes all documents. Find finds all documents.
Referencing
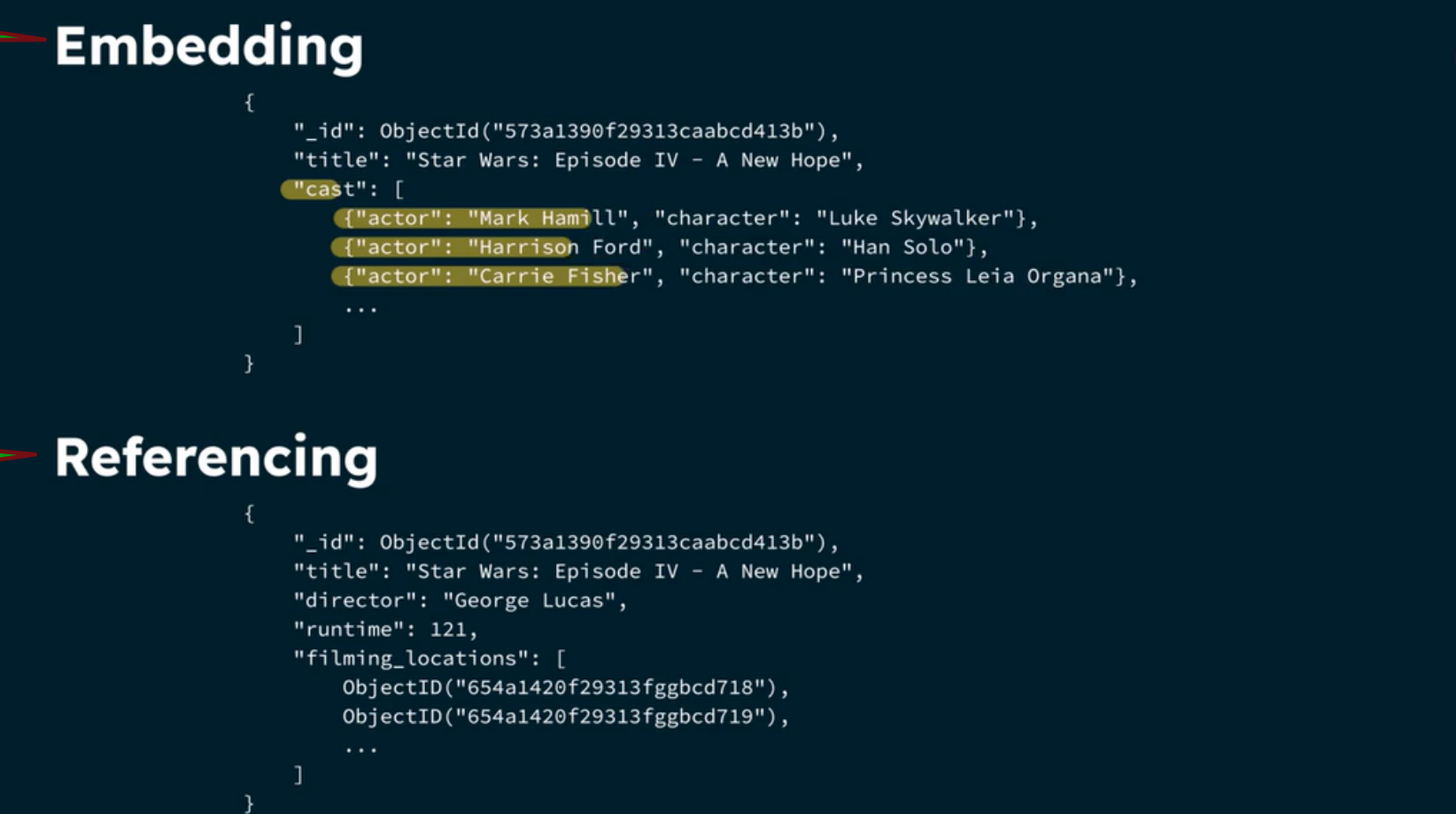
In MongoDB, we have two options for referencing. The first is embedding. Embedding duplicates the data entries such that each document is complete. The pros are we do not need to look elsewhere for the information, and it is fast. The cons are we can end up with a very large document with many redundancy. The second is referencing. Referencing does not duplicate the data, but it adds a OBJECTID in the document and we can search and link to the other documents to locate the information. However, this means that we search more slowly, and through more documents. But the document itself are smaller, without duplicate of information, easier to update and maintain proper records. Referencing is also closely related to the concept of data normalization.

Atomicity
Whenever we are working with multiple documents, we can use session to ensure atomicity. For example, we like to transfer money from accouter holder A to account holder B, this transfer involves the deduction from A and the increment of B. we want to ensure that both operations succeed together or fail together, but not one succeeded and the other failed (for instance, money taken out from A but not put back in B).
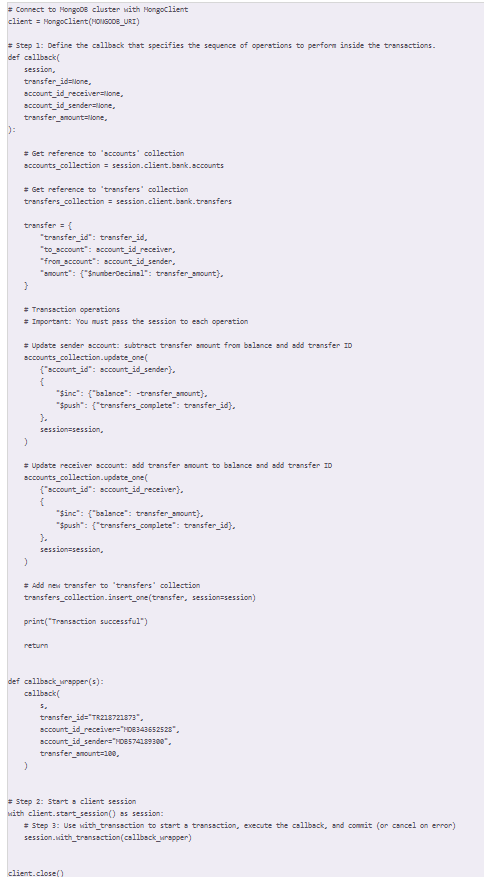
What is aggregates?
In MongoDB, the concept of aggregation refers to the process of processing data records and returning computed results. Aggregation operations group values from multiple documents together and can perform a variety of operations on the grouped data to return a single result. Aggregations are similar to SQL’s GROUP BY and JOIN operations, but they are more powerful and flexible.
Key Concepts of Aggregation in MongoDB
-
Aggregation Pipeline:
- The aggregation framework uses a concept called the “aggregation pipeline,” which is a series of stages that process the data. Each stage performs an operation on the input documents and passes the result to the next stage.
- The pipeline operates in a sequence, where the output of one stage becomes the input to the next.
- Example of an aggregation pipeline:
db.orders.aggregate([ { $match: { status: "shipped" } }, // Stage 1: Filter documents { $group: { _id: "$customerId", total: { $sum: "$amount" } } }, // Stage 2: Group and calculate total amount { $sort: { total: -1 } } // Stage 3: Sort by total amount in descending order ])
-
Stages in the Aggregation Pipeline: $match: Filters the documents to pass only those that match the specified conditions. Similar to the
WHEREclause in SQL.

$group: Groups documents by a specified identifier (_id) and applies an aggregation function to the grouped data (e.g., sum, average). Similar to the GROUP BY clause in SQL.

$sort: Sorts the documents based on the specified field(s) and order (ascending or descending).

$project: Reshapes each document in the stream, adding, removing, or transforming fields.

$limit: Limits the number of documents that are passed through the pipeline.
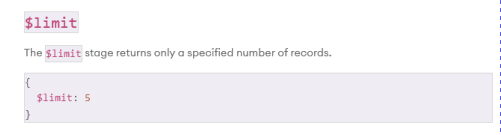
-
$skip: Skips a specified number of documents, often used in conjunction with
$limitto implement pagination.-
$unwind: Deconstructs an array field from the input documents to output a document for each element of the array. It is useful for dealing with arrays within documents. $lookup: Performs a left outer join to another collection in the same database to combine data from multiple sources, similar to SQL’s
JOINoperation.
-
$unwind: Deconstructs an array field from the input documents to output a document for each element of the array. It is useful for dealing with arrays within documents. $lookup: Performs a left outer join to another collection in the same database to combine data from multiple sources, similar to SQL’s
$Set: Insert or modify the values of a field.
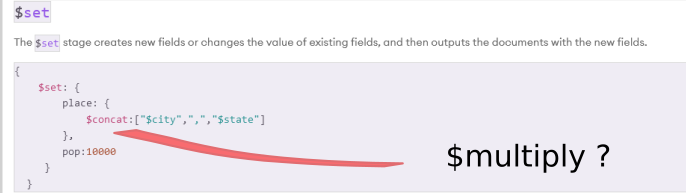
-
Aggregation Expressions:
- Aggregation stages often include expressions to perform operations on fields, such as arithmetic, string manipulation, and conditional logic. Example: In the
$groupstage, you might use Accumulator such as$sum,$avg,$max,$min,$count,etc., to perform calculations on grouped documents.
- Aggregation stages often include expressions to perform operations on fields, such as arithmetic, string manipulation, and conditional logic. Example: In the

-
Example Scenarios:
-
Calculate Total Sales by Product:
db.sales.aggregate([ { $group: { _id: "$productId", totalSales: { $sum: "$amount" } } } ])This query groups sales records by
productIdand calculates the total sales for each product. -
Find Top 5 Products by Sales:
db.sales.aggregate([ { $group: { _id: "$productId", totalSales: { $sum: "$amount" } } }, { $sort: { totalSales: -1 } }, { $limit: 5 } ])This pipeline groups sales by product, sorts them in descending order by total sales, and returns the top 5 products.
-
Calculate Total Sales by Product:
Save the new collections
- $merge: Allows the output of an aggregation pipeline to be written to a collection, either by replacing existing documents or merging the results.
- $out: Directly writes the results of an aggregation pipeline to a new collection.

Aggregation is a a way to create new collections from existing collections of documents or by modifying them. It is very useful for create a sub-set of documents as a new collections for subsequent analysis.
Comparison Operators
In MongoDB, $gt is a query operator that stands for “greater than.” It is used to compare a field’s value with a specified value and returns documents where the field’s value is greater than the specified value.
Syntax:
{ field: { $gt: value } }
- field: The field in the document you want to compare.
- value: The value that the field’s value must be greater than to match the document.
Example:
Suppose you have a collection called products with documents that look like this:
{
"_id": 1,
"name": "Laptop",
"price": 1200
},
{
"_id": 2,
"name": "Phone",
"price": 800
},
{
"_id": 3,
"name": "Tablet",
"price": 600
}
To find all products with a price greater than 800, you would use the $gt operator like this:
db.products.find({ price: { $gt: 800 } })
This query would return:
{
"_id": 1,
"name": "Laptop",
"price": 1200
}
In this example, only the document with the price of 1200 is returned because it is the only document where the price is greater than 800.
In MongoDB, $lt is a query operator that stands for “less than.” It is used to compare a field’s value with a specified value and returns documents where the field’s value is less than the specified value.
Syntax:
{ field: { $lt: value } }
- field: The field in the document you want to compare.
- value: The value that the field’s value must be less than to match the document.
Example:
Suppose you have a collection called products with documents that look like this:
{
"_id": 1,
"name": "Laptop",
"price": 1200
},
{
"_id": 2,
"name": "Phone",
"price": 800
},
{
"_id": 3,
"name": "Tablet",
"price": 600
}
To find all products with a price less than 800, you would use the $lt operator like this:
db.products.find({ price: { $lt: 800 } })
This query would return:
{
"_id": 3,
"name": "Tablet",
"price": 600
}
In this example, only the document with the price of 600 is returned because it is the only document where the price is less than 800.
In MongoDB, $lte is a query operator that stands for “less than or equal to.” It is used to compare a field’s value with a specified value and returns documents where the field’s value is less than or equal to the specified value.
Syntax:
{ field: { $lte: value } }
- field: The field in the document you want to compare.
- value: The value that the field’s value must be less than or equal to in order to match the document.
Example:
Suppose you have a collection called products with documents like this:
{
"_id": 1,
"name": "Laptop",
"price": 1200
},
{
"_id": 2,
"name": "Phone",
"price": 800
},
{
"_id": 3,
"name": "Tablet",
"price": 600
}
To find all products with a price less than or equal to 800, you would use the $lte operator like this:
db.products.find({ price: { $lte: 800 } })
This query would return:
{
"_id": 2,
"name": "Phone",
"price": 800
},
{
"_id": 3,
"name": "Tablet",
"price": 600
}
In this example, the documents with the price of 800 and 600 are returned because both prices are less than or equal to 800.
In MongoDB, $gte is a query operator that stands for “greater than or equal to.” It is used to compare a field’s value with a specified value and returns documents where the field’s value is greater than or equal to the specified value.
Syntax:
{ field: { $gte: value } }
- field: The field in the document you want to compare.
- value: The value that the field’s value must be greater than or equal to in order to match the document.
Example:
Suppose you have a collection called products with documents like this:
{
"_id": 1,
"name": "Laptop",
"price": 1200
},
{
"_id": 2,
"name": "Phone",
"price": 800
},
{
"_id": 3,
"name": "Tablet",
"price": 600
}
To find all products with a price greater than or equal to 800, you would use the $gte operator like this:
db.products.find({ price: { $gte: 800 } })
This query would return:
{
"_id": 1,
"name": "Laptop",
"price": 1200
},
{
"_id": 2,
"name": "Phone",
"price": 800
}
In this example, the documents with the price of 1200 and 800 are returned because both prices are greater than or equal to 800.
In MongoDB, the $in operator is used to match documents where the value of a field equals any value in a specified array. It is equivalent to the SQL IN operator.
Syntax:
{ field: { $in: [ value1, value2, ... ] } }
- field: The field in the document that you want to check.
- value1, value2, …: The values that you want to match against the field. If the field’s value matches any of these values, the document will be included in the results.
Example:
Suppose you have a collection called products with documents like this:
{
"_id": 1,
"name": "Laptop",
"category": "Electronics"
},
{
"_id": 2,
"name": "Desk",
"category": "Furniture"
},
{
"_id": 3,
"name": "Phone",
"category": "Electronics"
},
{
"_id": 4,
"name": "Chair",
"category": "Furniture"
}
If you want to find all products that belong to either the “Electronics” or “Furniture” category, you would use the $in operator like this:
db.products.find({ category: { $in: ["Electronics", "Furniture"] } })
This query would return all documents where the category field is either “Electronics” or “Furniture”:
{
"_id": 1,
"name": "Laptop",
"category": "Electronics"
},
{
"_id": 2,
"name": "Desk",
"category": "Furniture"
},
{
"_id": 3,
"name": "Phone",
"category": "Electronics"
},
{
"_id": 4,
"name": "Chair",
"category": "Furniture"
}
Use Cases:
-
Filtering by Multiple Values:
$inis useful when you want to filter documents that can match any value within a specified list. For example, finding all users with specific roles or all orders with certain statuses. -
Checking Membership in an Array: If a field contains an array,
$incan be used to check if any element of the array matches one of the specified values.
Key Points:
- If the field contains an array,
$inchecks if any of the elements in the array match any of the values in the specified array. -
$incan be used with both scalar values (e.g., strings, numbers) and arrays within documents.
The $in operator is a powerful tool for querying documents with multiple potential matching criteria, making it easier to handle complex filtering conditions in MongoDB queries.